“We were arrested at the Hungarian border and taken to the camp Stryi [a prisoner of war camp near Lviv in Ukraine], where we spent 12 days in prison. They brought a Jew to the camp, took everything he had, and gave him a rope to hang himself. The Germans didn’t pay attention to us because they took us for Russian prisoners, even the chief of police. When we began to protest that we didn’t want this Jew to hang himself in the prison, I received a good slap and a big kick in the kidneys. The head German came to find out what had happened. We told him that we didn’t want a man hanged in the prison, that this was a crime. He responded that it didn’t matter, that it was a Jew. We told him we were French prisoners of war and we did not want to be present for this crime. He took us into the office of the chief of police for several minutes. When we returned to the prison, we were left with the hanged man for another two hours. This is German civilization.“
The above testimony was one of several that French prisoners of war gave to Soviet investigators in 1944-1945 after being liberated by the Red Army in western Ukraine. Once the war was over, this French soldier returned to his life as a miner in a village in the north of France and left no other written record of what he had witnessed of the Nazi genocide of the European Jews.
Click on the text for a translation. The annotation of the document was made possible by Neatline (an Omeka plugin).
Photograph of the cemetery for French prisoners of war. USHMM, Herman Lewinter photograph collection, irn515114 / 1990.135.
Introduction
For decades after World War II, lack of access to Soviet documentation inhibited scholarship on the Holocaust in the East. Since the collapse of the USSR and the “archival revolution” that followed, scholars seem to have the opposite problem. But as archivists have long known and researchers soon discovered, physical access to materials on its own is not enough. Records of the Nazi occupation of the Soviet Union are scattered across repositories in what are now different countries, and the separation of regional collections from parent organizations in Moscow makes cross-referencing and contextualizing information difficult. This blog post explores how publicly available digital tools can facilitate navigation and discovery for research projects that rely on large bodies of documents from multiple locations.
No group of records illustrates the dilemma of too much information better than the archives of the Extraordinary State Commission (Chrezvychainaia gosudarstvennaia komissiia, ChGK). Stalin’s government created this organization on November 2, 1942 to gather evidence for the prosecution of war crimes and restitution for economic destruction that took place during the Nazi occupation. While the war was still ongoing, the ChGK oversaw investigations in the Belorussian, Karelo-Finnish, Moldavian, Ukrainian, and all three Baltic Soviet Socialist Republics, as well as the 28 oblasts (regions) of the Russian Soviet Federative Socialist Republic that were occupied by the Nazi regime. This undertaking produced more than 43,000 files stored in Moscow alone, as well as another several thousand presently dispersed across the western regions of the former USSR. My dissertation analyzes the ChGK’s work throughout occupied Soviet territory on the local, regional, central, and international levels over the course of the war to determine how knowledge of the Holocaust developed in the USSR. Extrapolating from the case studies I examine and additional records available within the EHRI portal, I would estimate that another 30,000 files exist in post-Soviet national and regional archives. This enormous body of materials presents researchers with numerous opportunities for exploration, but also with the risk of becoming overwhelmed with the sheer number of documents.
Wartime, postwar, and post-Soviet complications
During and immediately after the war, the scope of the ChGK’s endeavor produced challenges surrounding how to manage information and personnel, how to enforce uniform quality of investigations and reporting, and how to ensure investigatory work was completed at all in a country still reeling from the consequences of Nazi occupation. The ChGK’s internal communications make it clear that just as members of the central ChGK in Moscow struggled to manage regional commissions, regional leaders had to fight for control over local operations in the field.
Click on the text for a translation. The annotation of the document was made possible by Neatline (an Omeka plugin).
Photograph of Soviet investigators. USHMM, Herman Lewinter photograph collection, irn515114 / 1990.135.
Echoes of these challenges pervade the literature on the Holocaust in the USSR that has rapidly expanded since the ChGK’s archives first became available for research after 1991. In many cases, logistical difficulties in interpreting ChGK records (assessing accuracy, identifying bias, deciphering handwriting, and so on) have led scholars to generalize conclusions on the nature of Soviet investigations of Nazi crimes as a whole based on the study of single locales. On the contrary, a broad overview of the historiography indicates that investigations differed significantly from place to place, as well as with the passage of time.
To identify and critically interrogate these variations, my dissertation tackles the ChGK by examining groups of investigations that took place in diverse locations at different stages over the course of the war. It also integrates documents submitted to Moscow with materials retained by lower-level commissions (such as correspondence and draft reports). To date, I have acquired documents from roughly three-fourths of my designated repositories (18 of 25), amounting to 1.5 terabytes of data (more than 543,000 images) from archives in Belarus, Estonia, Latvia, Lithuania, Russia, Ukraine, and the United States, including the former KGB archives in Ukraine and the three Baltic countries. My biggest puzzle has been how to identify overlap, patterns, and divergences effectively – essentially, how to maintain intellectual control over such a large number of materials.
Cloud-based archive
In my case, any solution needed to be simple and easy to incorporate into the research process, as creating a database was not my central project. The first thing I do upon acquiring digital surrogates is rename the file to reflect record group and subgroups, to retain the hierarchy of source archives and recognize where the file came from just by looking at the title. Second, for materials directly related to my dissertation case studies, I code documents using Microsoft Excel and a controlled vocabulary to make them searchable by interrogator, witness, and other components, as well as for the presence or absence of information on local collaborators and victims explicitly identified as Jewish. Third, I mirror the collection in Google Cloud, which enables me to use Google search functionality to find information within my digital archive.
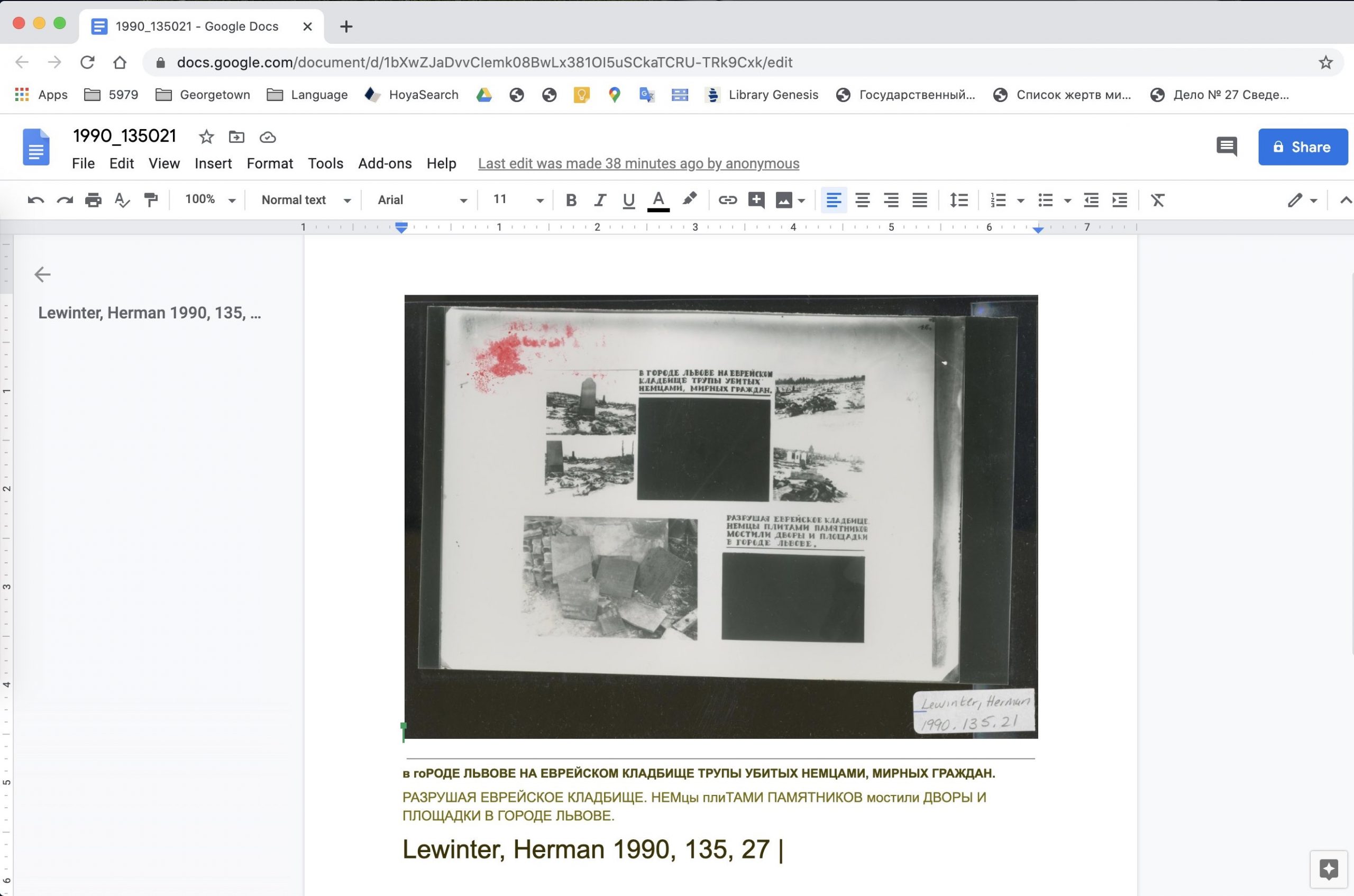
TEXT RECOGNITION: In the city of Lviv at the Jewish cemetery, the corpses of peaceful citizens killed by the Germans. Destroying the Jewish cemetery, Germans paved yards and grounds with memorial gravestones in the city of Lviv.
Crucially for my research, Google Cloud performs optical character recognition (OCR) on most image formats in multiple languages automatically, converting both printed and handwritten words into digital text stored as file metadata. This data remains private to my account and is not processed for advertising purposes, but is available for me to search within the application. The results are not perfect. For documents such as those of the ChGK, which were often of poor quality during the war and have only deteriorated since then, Google cannot hope to recognize every iteration of a search term. A problem at the opposite end of the spectrum is “false positives,” when a Google search retrieves files that turn out to be irrelevant. To assess accuracy, I can reference and download the text used for searches by opening the image file within Google Docs. Thus, although a fallible method, storing my source materials within Google Cloud equips me to identify connections between documents that otherwise I would miss.
For example, I first became interested in French prisoners of war who testified for the ChGK investigation of Nazi crimes in Lviv oblast the old-fashioned way, after stumbling upon testimonies in French preserved within the ChGK secretariat’s records for a report on the region published in the Soviet press. Within the ChGK’s investigatory files for Lviv oblast, I found another several original testimonies from French prisoners of war. I did not think to look for these witnesses in materials for other oblasts in Ukraine. It was only through searching for the soldiers’ surnames within my cloud-based archive that I uncovered another group of original testimonies from these same men among the investigatory files for Ternopil oblast (including the testimony quoted above), because Google was able to flag one of their names within a handwritten document.
Trial and error and serendipity
My discovery that French prisoners of war participated in multiple Soviet investigations of Nazi crimes illustrates the potential of digital assistive technology, but of course Google is no substitute for reading materials oneself. Nothing on my computer or in the cloud could save me from transliterating incorrectly the surname of a French prisoner of war whose testimony I had only in Russian, which then prevented me from locating him the first time I tried to find French witnesses for the ChGK in archives in France. At the same time, in the dossier for another French ChGK witness from the archives of the French Ministry of Defense, when I came upon documents submitted by a Soviet engineer in support of the French former prisoner of war’s application for a pension, it was thanks to Google that I knew these two men first encountered each other 30 years earlier while documenting Nazi atrocities in the city of Ternopil.
To be sure, a more robust technology, particularly one tailored to the specific characteristics of the ChGK’s materials, would produce more accurate results more consistently. Extensive preprocessing of data would also allow for research questions that depend on information not explicitly articulated in the documents. But for my project, Google Cloud has made it possible to grapple with a far greater breadth of the ChGK’s records than would have been possible on my own. More often than I would have predicted, even Google’s “false positives” are useful, because they force me to reencounter and consider side by side records that otherwise might languish in the depths of my cloud-based archive.
By fostering discoverability across a broader scope of materials, digital tools such as Google Cloud enable scholars to approximate an overview of what we now call the Holocaust, a vantage point only the Nazi regime had during the war. Now that I am more advanced in my research, when I search for the surnames of my French witnesses, I find these men not only within the ChGK’s archives and French documents, but also among materials the Soviet prosecution submitted for the Trial of the Major War Criminals at Nuremberg as well as records of the former KGB in Kyiv. The use of relatively simple digital tools (from the user’s perspective) has enabled my research to transcend certain challenges inherent to its large, complex source base. My hope is that moving forward, similar digital methods will further contribute to the shedding of new light on the Holocaust in the USSR and elsewhere in Europe – by facilitating lines of inquiry that crisscross archival boundaries, without getting lost in the process.
Robert Parzer
It is great to read from another researcer who also uses Google Drive in order to make the collected ressources productive. I also use it since several years and could not imagine anymore workin without it. It enables me to find testimonies, mentions of places and quotes otherwise out of reach.