Introduction
Digital technologies are successfully applied in cultural heritage projects supporting digitization of cultural objects, metadata creation, metadata maintenance, creation of digital infrastructure for cultural heritage research and many others. When we discuss archival digital textual content, some of the most imminent tasks are related to automatic metadata generation, searchability and preservation and these can be helped by services for automatic semantic annotation. In this blog we discuss the applicability of such services for automatic extraction of person names and locations from Oral History Transcripts provided by the United States Holocaust Memorial Museum (USHMM). The algorithms for automatic information extraction can work with comparatively high accuracy when applied in a close domain, they are especially helpful and could greatly speed up the human work when large volumes of data are to be processed.
Person Extraction Service
The automatic extraction of persons’ names in the EHRI textual resources is an important task for Holocaust digital research. Being able to automatically identify persons’ names allows for:
- automatic metadata enrichment of the available resources and thus for better semantic indexing and search;
- improved document retrieval for specific people;
- better research related to groups of people affected by the Holocaust;
- automated names authority list creation, etc.
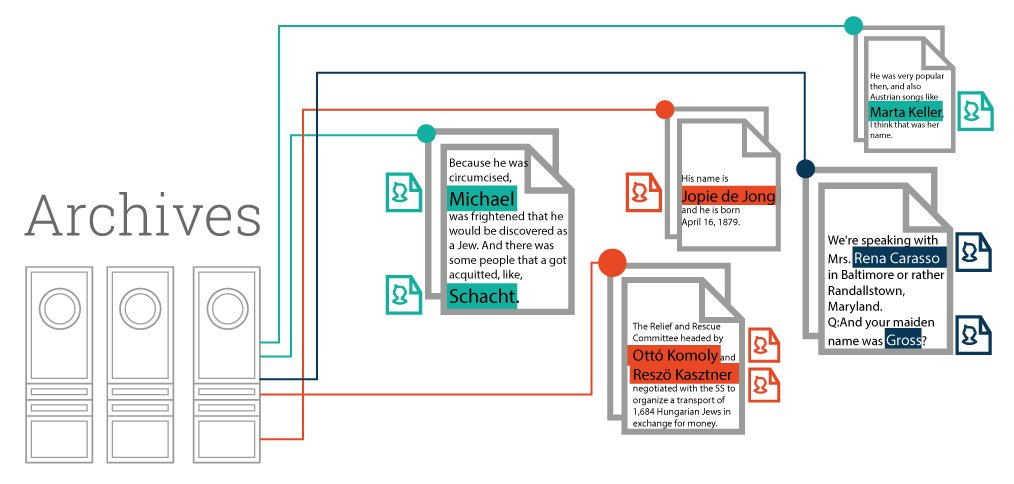
For the purposes of EHRI2, we developed a high-performance person extraction service. It is based on a named entity recognition pipeline designed for the news domain and later tuned to the specific needs of EHRI. A corpus of 70 synthetic documents (generated from the USHMM testimony files), containing 200 sentences each was manually annotated for names of persons and locations. It served as a development and evaluation corpus for the task. With simple words this would mean that with part of the corpus we learned how our data looked like and tuned our service and with the other one, which remained hidden until the end, we tested the performance. The corpus is supported by detailed manual annotation guidelines describing positive and negative examples. For the purpose of the annotation task, a crowd-sourcing platform was deployed, it facilitated the annotators to prepare the gold corpus. The annotators were given documents which were automatically annotated with an initial version of the pipeline which produced imperfect machine annotations, they curated those annotations and turned them to gold standard ones.
Names Challenges
As one can imagine, the names we see in the news are different from those in Holocaust-related documents – the first ones are popular names of people that are often described in publicly available resources like Wikipedia, while the latter ones are mostly names, we see only in the Holocaust archives and a few of them only appear in sources like Wikipedia. Moreover, the context in which the names are mentioned is different in these two types of texts, while the news are written with comparatively short and clear sentences, the testimonials contain very long sentences with many references to people and locations, sometimes the people who speak, lose their thought and the messages are not very clear. Since the context and grammaticality of the text are important features for the algorithms that learn to recognise named entities the above mentioned characteristics also influence the performance of the service. Therefore some adjustments were necessary in order to adapt the initial service developed for the news domain to the specific needs of EHRI.
The challenges in processing historical documents or transcripts of personal testimonials come from the nature of the texts on one hand, and from the nature of the supporting knowledge we use in our information extraction service on the other. The supporting knowledge in this case combines various lists of names, linked open data like DBpedia where popular persons, locations, organisations, events etc. are described in a structured format, which help us to identify in the text the strings which represent personal names related to the Holocaust.
Challenges coming from the documents
During the development of this service, we examined our target documents – the oral transcripts of Holocaust survivors – and here is what we found. The transcripts of the testimonials were done through a crowdsourcing platform by volunteers who listened to the materials and wrote down what they heard. The problem is that many of the stories mention locations in Europe, and especially Eastern Europe, that are either not so popular or can have alternative transcriptions when written with Latin characters. Therefore different volunteers could produce different transcription for one and the same location. The same is valid for the persons’ names. Eastern European and Jewish names are not simply transcribed in Latin characters. Moreover, the interviewees sometimes speak indistinctly and the names they mention couldn’t be heard well by the volunteers who needed to transcribe them. The result is that there many erroneous names of persons and locations or names which have alternative transcriptions.
Challenges coming from the supporting knowledge
In order to adapt the pipeline to the specific needs of the EHRI documents (the USHMM testimonials being our playground), we needed external knowledge, name banks and authority lists that would help us to find out the names in the text thus perform the task with higher accuracy. DBpedia was already integrated in the initial news domain solution, so the next most suitable resource to be integrated turned out to be the USHMM Holocaust Survivor and Victims Database (HSV Database) with all the names of the people mentioned in it. It contained over 3.2 M person records (as of May 2015) and additional 1M names of their relatives. Although there were duplicates in the names, this looked like a good source for names of people affected by the Holocaust and it could help us improve our service. The use of this database came with a price. Being collected from various sources and with different methods over a long period of time, the database contained numerous problematic entries such as:
- Misspelled names – these are considered names which occur only once in the database, for them we create an alternative transcription according to the closest distance to a number of other names in the database;
- Names containing punctuation marks and other special characters instead of letters – “Baruch DA…CH”, “Freyde ()per”, “´elyada` Froynd”;
- Names containing numbers – “Vera 80318Vogl”;
- Names containing wildcards – “Ben..* Sperberg”;
- Concatenation of two names in the same record;
- Addresses written in the name field – “14 Flinders Street Breitstein”;
- Names containing abbreviations – “J.G.”.
We corrected the erroneous entries or filtered them out the ones for which corrections wouldn’t be helpful and then we employed the so-cleaned up database.
Person Extraction Service Fine-tuning
Although there are problems in the testimonials we could not address, we could still correct many of the inconsistencies coming from the supporting data. As a first step, we elicited a set of rules to help us clean up the names we extracted from the USHMM HSV Database. The so-created list of names was supplied as a trigger list to our service, which facilitated the tagging of the candidate persons’ names. After the initial simple matching against the trigger lists, we applied a pipeline of procedures that helped us decide whether the tagged string was indeed a personal name or another expression. After each improvement of the process, we evaluated the current stage of the system against its initial performance. The reference corpus for the evaluation was the unseen part of our manually annotated gold corpus. After introducing the set of names from the USHMM HSV, the F1-measure of the system already increased with 11% compared to the existing system.
The next improvement we did was to allow our person extraction service to tag single names. In news, we consider a string as a personal name only if this person is mentioned at least once with her/his full name. E.g., if we see “Barack Obama” and then only “Obama” in a news article, we would tag both names. However, if we see only Obama in the whole article, we wouldn’t, as this does not comply with the style news are usually written and probably the name Obama in this case means something else.
In the testimonials, the narrative does not follow any such rules. People normally talk about their relatives or close friends using only their first name or a nickname. Or they speak of people whose full name they did not know and would often mention only the first name or the family name. By allowing the pipeline to tag single names like these (only first name or only a family name), we improved the performance by 19% and reached 75% F1.
Finally, after an extensive error analysis, we could come up with a set of additional fine tuning rules that helped us reach 77% F1, which is 33 points above our initial state. This is the current version of the pipeline uploaded to the Ontotext infrastructure.
Location Extraction Service
When we talk about location extraction from text, we mean two things:
(i) Spotting which words or phrases in the text refer to a location. We call this entity tagging.1 E.g., in the sentence “Laura lives in Sofia.”, the word Sofia refers to a location however it is not clear exactly which Sofia.
(ii) Once we know which are the entities in the text, we want to link them to a knowledge base (such as GeoNames) where each location features a unique ID. This way we will know exactly which location is mentioned in the text. We call this task entity linking.2 E.g., In the example “Laura lives in Sofia.” if we don’t know the context of the situation, it is hard to say whether Sofia is the capital of Bulgaria, a city in Nigeria, a city in Mexico, an administrative region in Madagascar or any of the other. However, if we know the context, we can decide which is the correct concept to link Sofia to. E.g., “Laura moved to Bulgaria 5 years ago and now she lives in Sofia.” Now, we can determine that the Sofia where Laura lives, is the capital of Bulgaria. We call this entity disambiguation and we can add a link from the tagged entity Sofia to the concept in GeoNames with ID 727011.3 The latter one is also called georeferencing.
Within EHRI2, we have established a georeferencing service that uses GeoNames and DBpedia/Wikidata to find place references in text, access points and local databases.
Similarly to the person extraction pipeline, we used a location extraction pipeline developed by Ontotext, based on commercial applications, and extended it to suit the specific EHRI domain needs. It makes use of a hybrid approach, which combines machine learning algorithms and refinement rules.
The algorithm was re-trained and evaluated on the same Gold Standard Corpus as explained in the Person Extraction Section above. The corpus was developed by manual curation of automatically annotated documents through a crowd-sourcing platform. It was developed in accordance with detailed guidelines specifying positive and negative examples. E.g., neither of the following are places because they refer to organizations, institutions, papers, ships, etc.
- University of [Chicago], [Tel Aviv] university, Veterinary Institute of [Alma-Ata];
- The interview was given to the [United States] Holocaust Memorial Museum on Oct. 30, 1992;
- in the Theater de [Champs Elysee];
- [Washington] Post”, “[Washington] Monthly;
- USS [America].
We developed sophisticated disambiguation mechanisms, which select the appropriate location from our knowledge base when more than one candidate exist. The disambiguation is supported by EHRI specific rules that rely on the following place characteristics:
- Place names – we use a variety of synonym labels (Wikipedia redirects) and languages; e.g., Oświęcim, Освенцим, Auschwitz, Auschwitz-Birkenau, Birkenau, Konzentrationslager Auschwitz, KZ Auschwitz.
- GeoNames feature types: e.g., a number of irrelevant place types (e.g., hotels) are removed.
- Place hierarchy – when a place is mentioned near its parent place, this allows us to disambiguate the child. This is especially important for Access Points, which often mention the place hierarchy and not much more context, e.g.:
- “Moscow (Russia)” – as opposed to the 23 places of the same name in the US and a few more in other countries;
- “Russia–Moscow”;
- “Alexandrovka, Lviv, Ukraine” – “Alexandrovka” is a very popular village name. So, although this doesn’t lead to a single disambiguated place, it helps to reduce the set of possible instances from about 70 to about 20.
- Co-occurrence statistics based on Gold Standard over news corpora.
- Population – for populated places, we give priority to bigger places.
- Places nearer Berlin are given priority.
An additional feature of the service is that if it finds several hierarchical places in one access point, it outputs only the most specific places.
E.g.: “Moscow–Russia, Wilna–Poland” will be disambiguated to the following 3 places: “Moscow” (the capital of Russia), “Vilnius” (the capital of Lithuania) and “Poland”. Although Russia is present in the input access point, it is not present in the output, because the service understands that Moscow is more specific place and supplying it as output is enough. In the next section on the historic belonging of Vilnius we’ll make it clear why Wilna and Poland are both supplied in the output.
Georeferenced place names are useful for various purposes:
- Geo-mapping of textual materials, as shown below.
- Other geographic visualizations, e.g., of detention/imprisonment vs liberation camps?.
- The place hierarchy can be used to extract records related to a particular territory, e.g., “Archival descriptions mentioning Ukraine” should find all records mentioning a place in Ukraine.
- Coordinates can be used to map places and compute the distance between places.
- Places are an important characteristic to consider when deduplicating person records.
- Certain probabilistic inferences can be made based on place hierarchy and proximity.
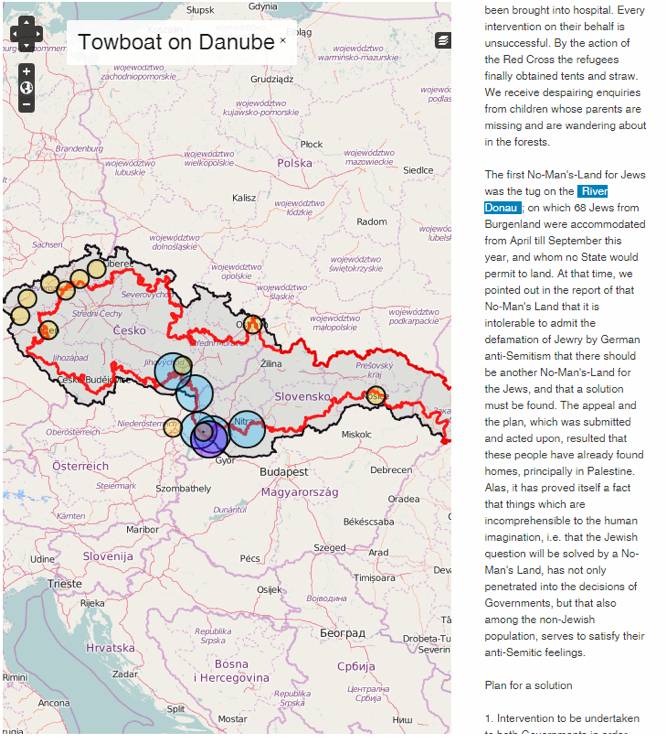
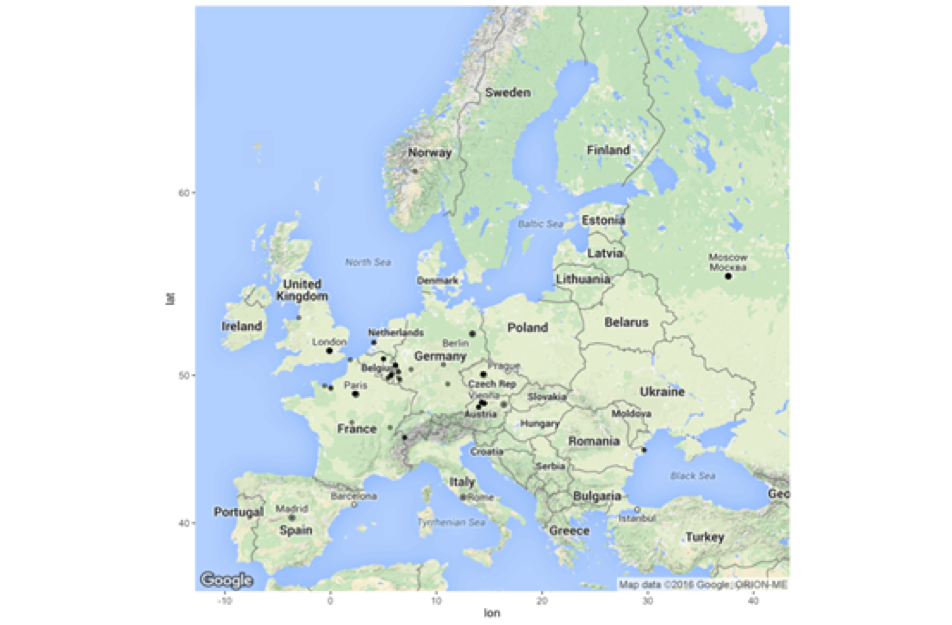
Geographic Challenges
A significant challenge we faced was the (in)adequacy of LOD sources for historical geography. When Nazis occupied a country, they established their own “Nazi geography”:
- The Nazis renamed place names, e.g., Oświęcim->Auschwitz, Brzezinka->Birkenau.
- The Nazis established new administrative districts, e.g., Reichskommissariat Ostland4 included Estonia, Latvia, Lithuania, the Northeastern part of Poland and the West part of the Belarusian SSR.
In addition, other historical processes changed borders, place names and administrative subordination. For example, Wilno (Vilna) was part of Poland until 1939, when USSR gave it to Lithuania to become its capital Vilnius.
While the GeoNames database often includes historical place names and even historical countries such as Czechoslovakia, the GeoNames place hierarchy mainly reflects modern geography. Currently, our geo-service uses the following:
Wilna–Poland is disambiguated as the two places Vilnius as part of Lithuania and Poland.
We have also considered local GeoNames additions such as making Czechoslovakia the parent of Czech Republic and Slovakia.
EHRI has a list of 261 Nazi administrative districts,5 which is also available as SKOS at http://data.ehri-project.eu/. However, these need to be linked to LOD (e.g., DBpedia) and the territorial hierarchy needs to be established.
E.g.: Reichsprotektorat in Böhmen und Mähren6 should be linked to Protectorate of Bohemia and Moravia7
We are considering some other sources of historical geography, e.g., the Spatial History Project.8
A Demonstration Use Case applying NER Tools Integrated Within an Existing Museum Catalog
Cataloging staff sometimes have the difficult task of processing large amounts of textual data in order to write descriptions, identify keywords, and apply controlled vocabularies. USHMM Collections Search relies heavily on this work to ensure researchers and other users are able to query for and discover what is most relevant to them. With this important responsibility at the forefront of our work, we are always seeking ways to enhance the thoroughness, correctness, and completeness of our descriptive metadata.
To this end, we wanted to explore how computational information extraction techniques, specifically named-entity recognition, could assist catalogers with processing oral history testimonies, when those oral histories are already associated with textual transcriptions of the spoken words. Continuous research in the area of natural language processing along with the ability to quickly and affordably offload computationally intensive tasks to the cloud has made it more accessible than ever to explore practical applications of these methods on large inputs.
Leveraging Ontotext’s location extraction service and Google Cloud’s more general natural language service, USHMM staff built a prototype of an application that can extract named-entities from oral history transcripts (sometimes numbering hundreds of pages) in a matter of seconds. The application, written using JavaScript and PHP, performs the following:
- Makes a request to our Apache Solr index to fetch the transcription
- Sends the transcript text to the named-entity recognition pipeline for processing
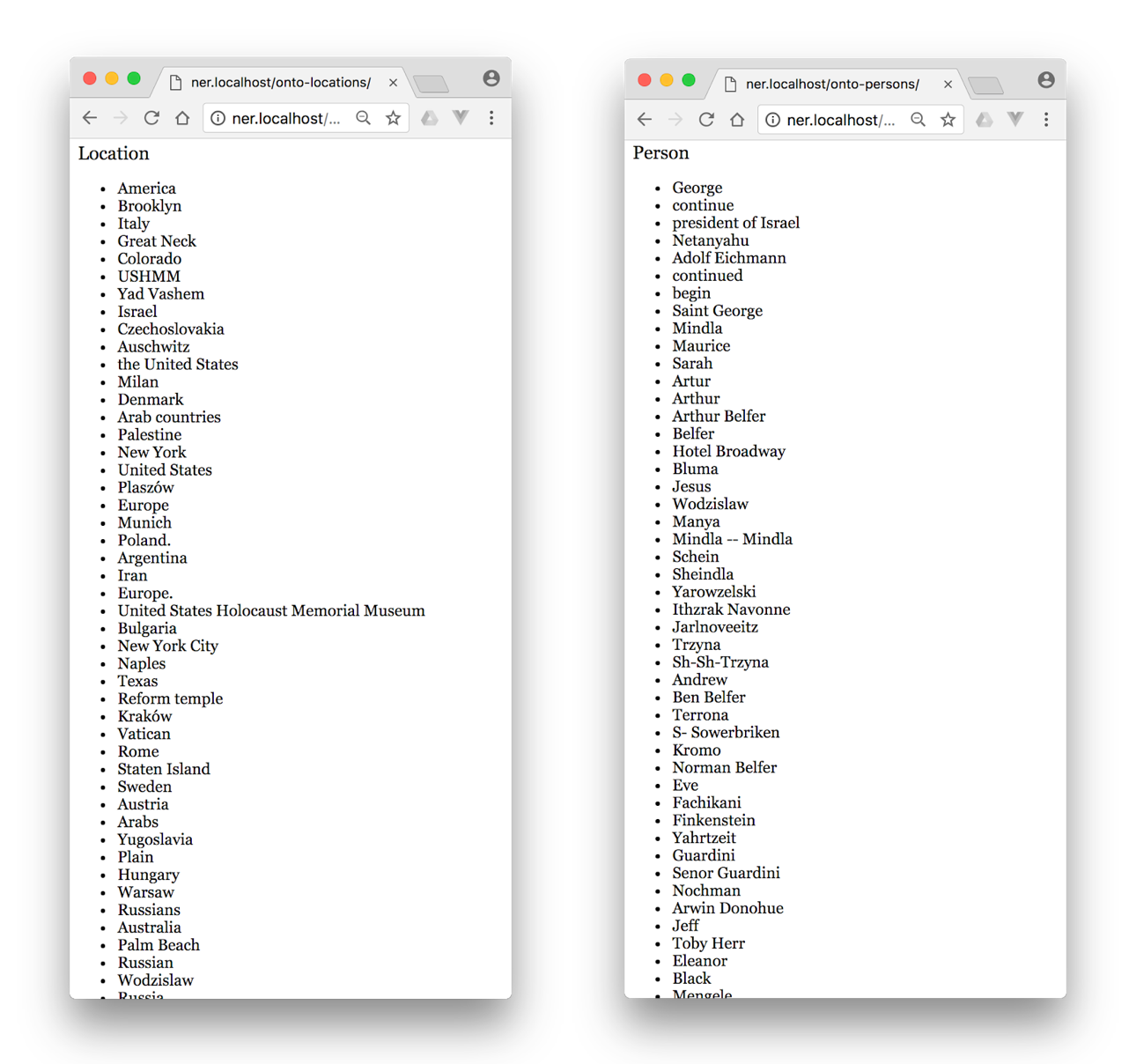
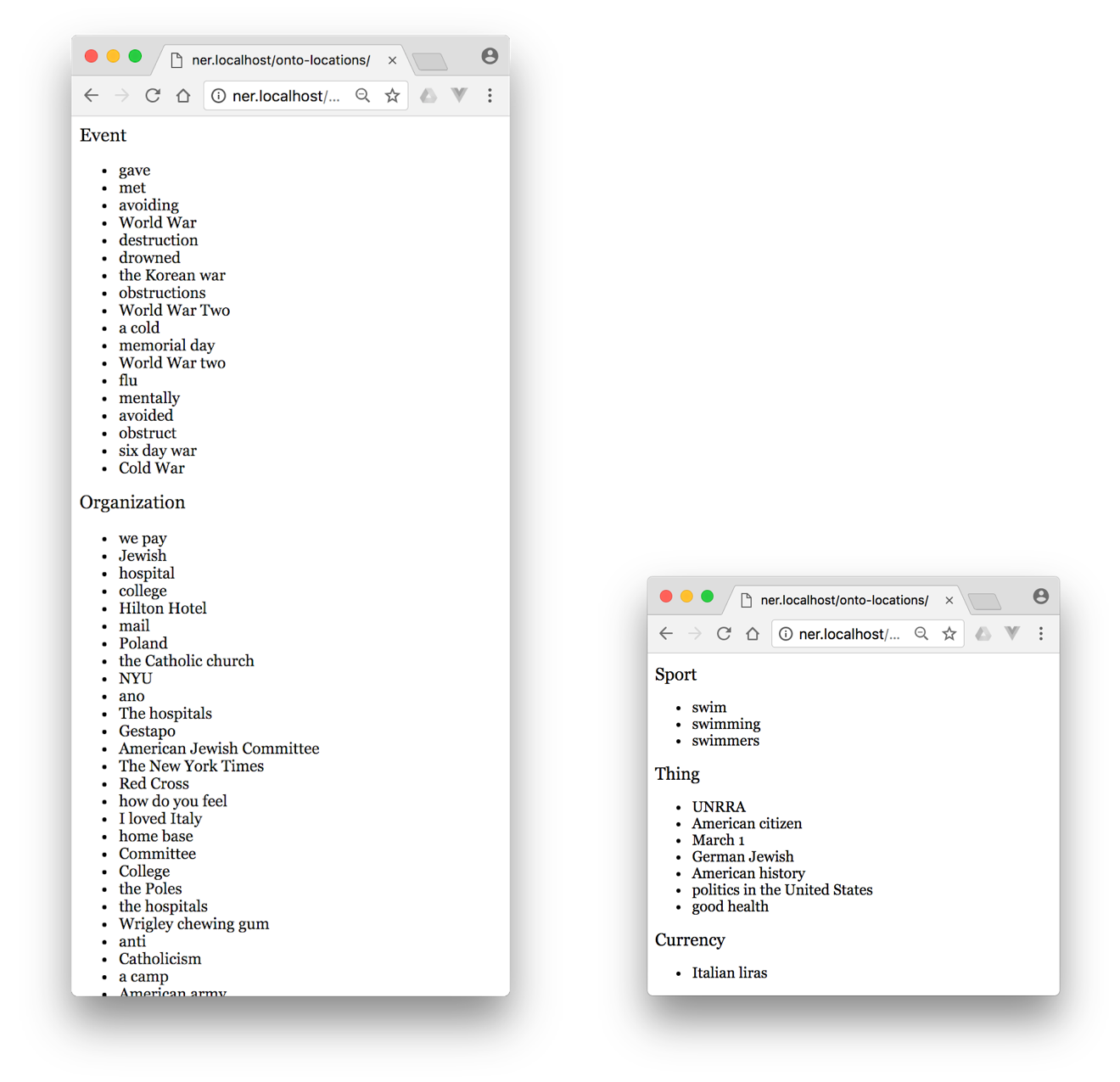
- Parses the JSON response to:
- Exclude nominals or common nouns
- Group the remaining entities
- Send location entities to GeoNames to obtain coordinates
- Geolocation data returned from GeoNames are plotted onto a dynamic, zoomable map using a combination of LeafletJS (mapping API), OpenStreetMap (map data), and Mapbox (tile imagery).
USHMM’s Collections Search is a highly customized catalog discovery and access system based on the open source Blacklight project, which is a Ruby on Rails application. Because USHMM staff was already well versed in developing this application further, it was possible to modify a test instance of Collections Search so that a link on an Oral History record page launches a new browser page that displays the results of the NER outputs listed above for that Oral History record.
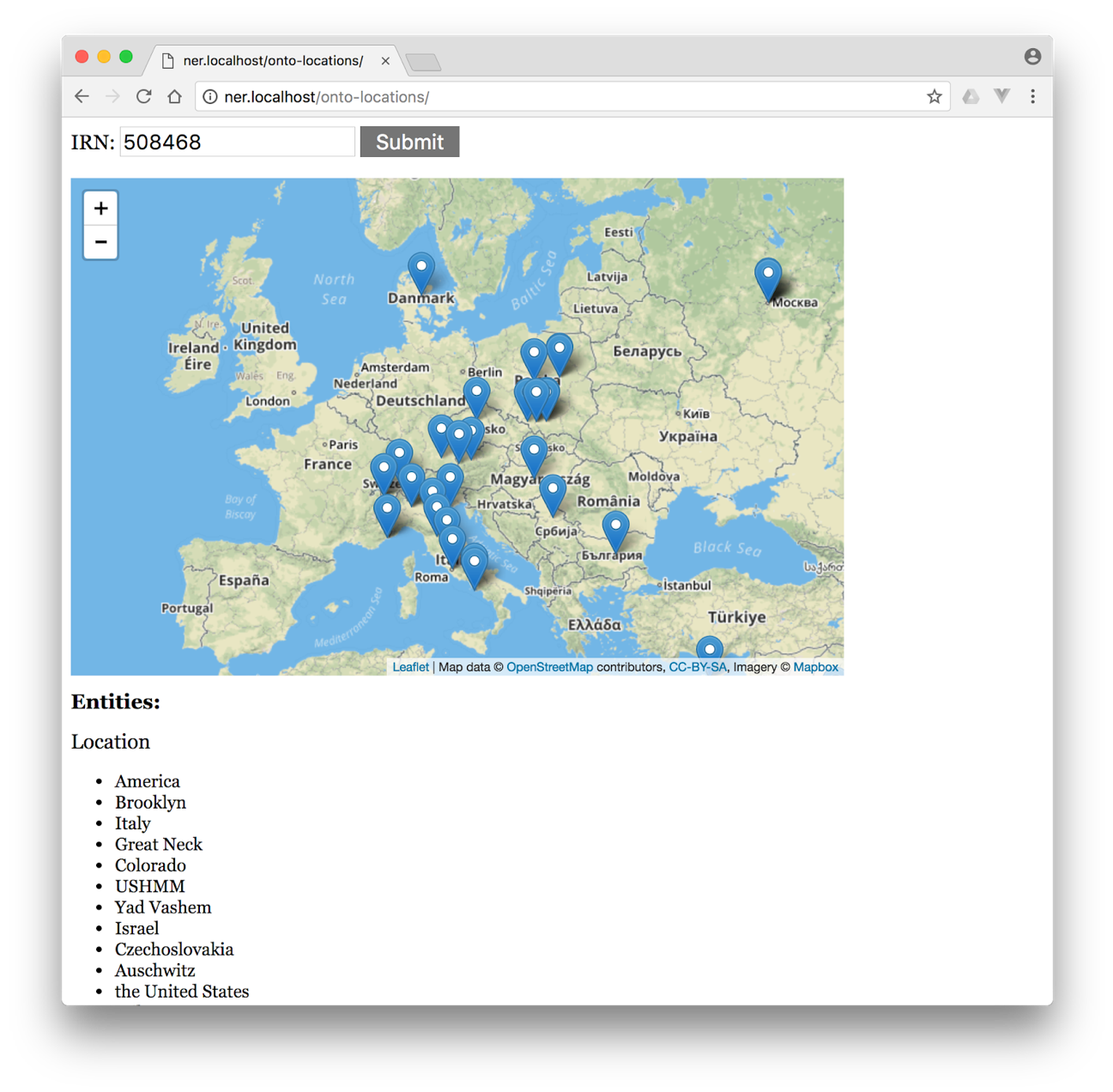
We asked one of the oral history catalogers at the museum to provide us with feedback on the perceived value of a tool like this. Her initial thought was that it would certainly expedite the process of analyzing/scanning a transcript— something that is very time consuming. After having a chance to experiment with the application on a particular oral testimony, she noted the following:
“I had some very positive results!
I added 30+ keywords. Also because of the demo I was able to identify a geographic place name that was not yet in the Library of Congress Name Authority File: Neyron (France).
I found that the most useful categories were location, organization, and event.”
As a result of our initial work, we think there is certainly potential for named-entity recognition to assist catalogers with processing historical testimonies. It can provide new insights and facilitate extraction of more metadata at a faster pace. This will ultimately bolster the discoverability of our collection to better serve our users.
Notes
- Entity tagging – also known as Named Entity Recognition: https://en.wikipedia.org/wiki/Named-entity_recognition ↩
- Entity linking – also known as Named Entity Disambiguation: https://en.wikipedia.org/wiki/Entity_linking ↩
- http://www.geonames.org/727011/sofia.html ↩
- https://portal.ehri-project.eu/authorities/ehri_cb-420 ↩
- https://portal.ehri-project.eu/vocabularies/admindistricts ↩
- https://portal.ehri-project.eu/keywords/admindistricts-212 ↩
- https://en.wikipedia.org/wiki/Protectorate_of_Bohemia_and_Moravia ↩
- https://web.stanford.edu/group/spatialhistory/cgi-bin/site/pub.php?id=51 ↩