
Kazerne Dossin – Memorial, Museum and Documentation Centre on Holocaust and Human Rights opened its doors on 1st December 2012. The institute inherited its archival collections from its predecessor, the Jewish Museum of Deportation and Resistance (JMDR). The JMDR had been inaugurated in 1995 at the former SS-Sammellager Mecheln, better known as the Dossin barracks, in Belgium. Between the summer of 1942 and 1944 over 25,500 Jews, Roma and Sinti were deported from here to concentration camps the East, mostly to Auschwitz-Birkenau.
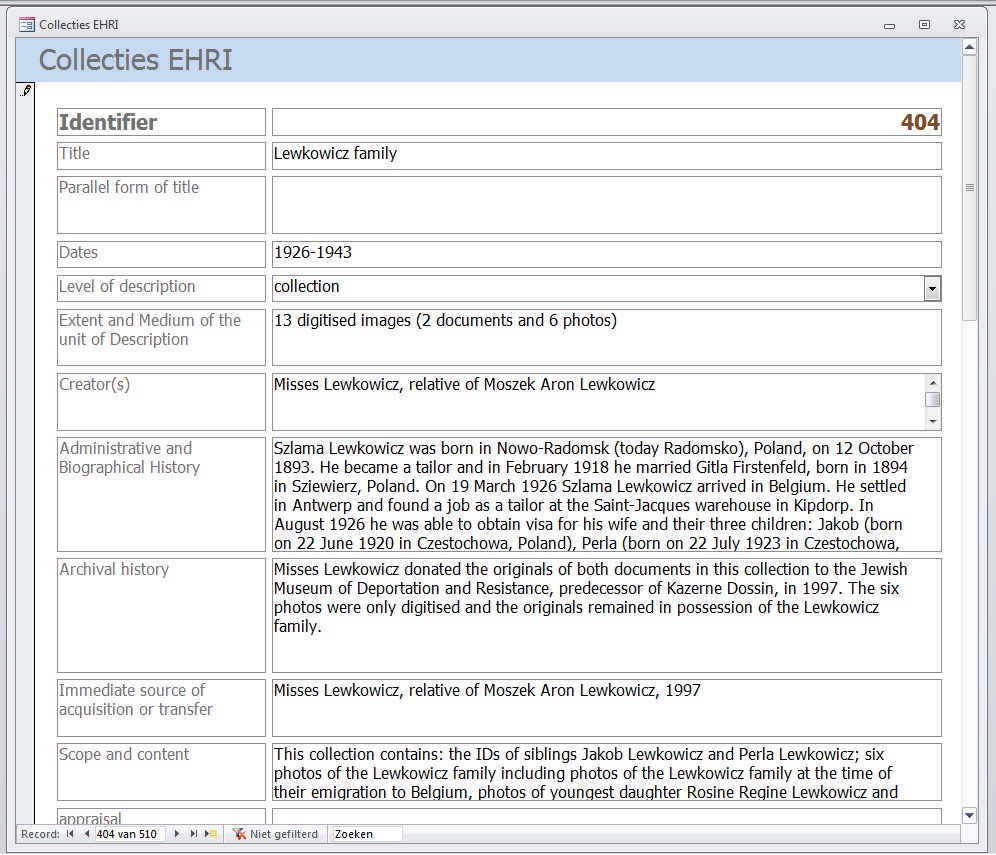
From the mid-1990s onwards the JMDR collected archival materials on the Holocaust in Belgium. The way in which these were catalogued and made available to the public changed dramatically over the past few years as Kazerne Dossin and EHRI became partners in sharing (meta)data with a broader audience. Using the example of the Lewkowicz family collection (unique, persistent identifier KD_00404) this article focuses on the evolution Kazerne Dossin went through while standardizing descriptions, and on the tools EHRI provided to optimize the workflow for collection holding institutes, a process from which Kazerne Dossin benefited as a test case.
The Birth of an Archival Collection
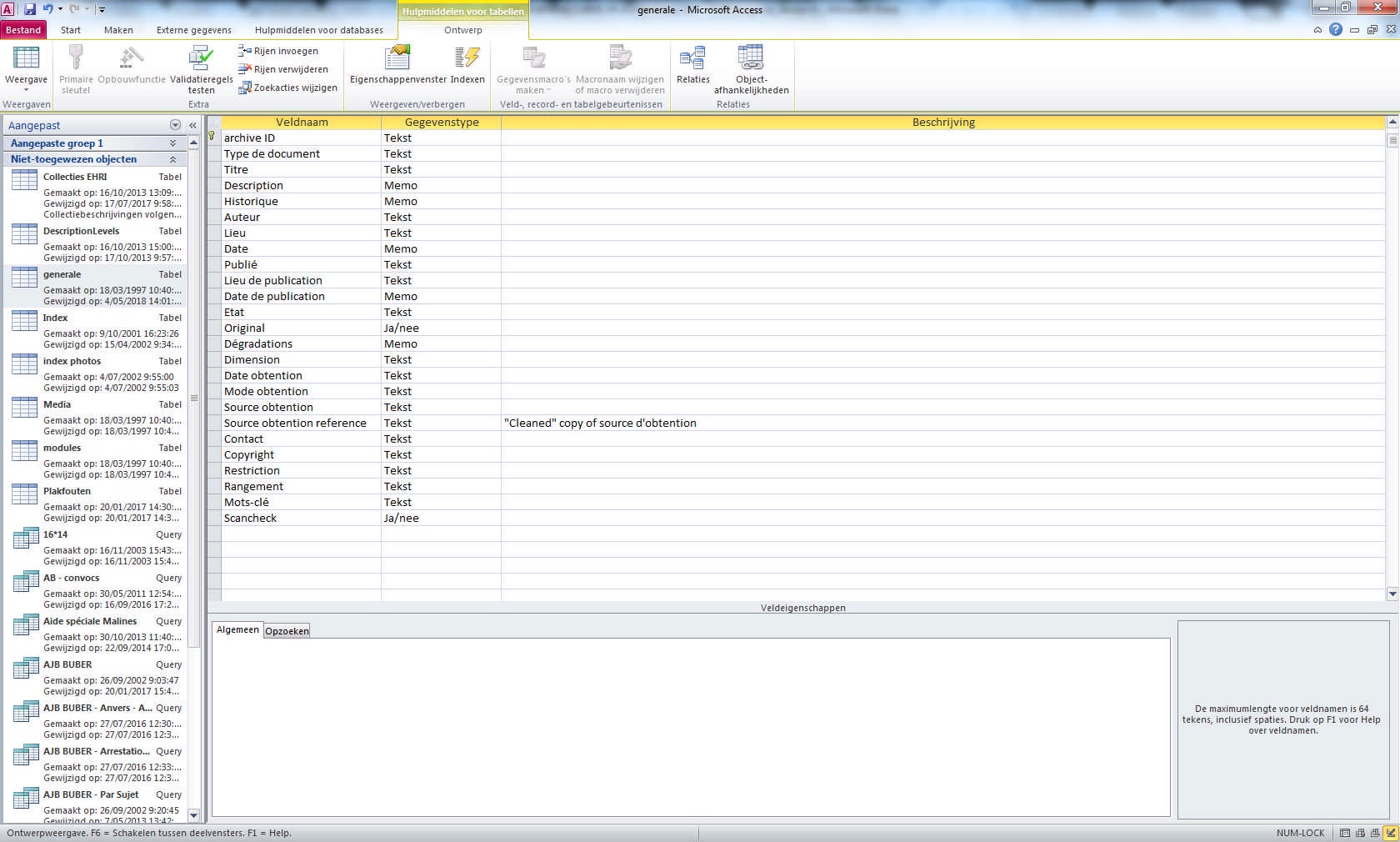
In 1994 a small team of two researchers started to collect documents, photos, objects, testimonies and other relevant archival materials to create the Jewish Museum of Deportation and Resistance’s permanent exhibition. To facilitate and catalogue all possible objects for the exhibit, all items – whether they were obtained physically or digitally, and whether they fell under the copyright of other institutes or under the copyright of the JMDR itself – were described in French on item-level in one large MS Access database.
Each item received a persistent, unique identifier and was attributed to one of four archival series: the A-series for documents and objects, the J-series for newspapers and magazines, the P-series for photos and the T-series for precious prints. The items were thus rather organised according to museum standards and not as a unit on collection level. Each of the four series had its own consecutive numbering and four customized metadata schemas. These were not compliant with the international archival standards: the museum staff developed their own standard.
As a result of the inauguration of the JMDR in 1995, survivors started donating their private collections to the JMDR. The accumulation of these valuable archival sources and information consequently led to the establishment of a documentation centre onsite. The staff members continued to describe archival additions on item-level in French according to the metadata schemas that were developed for exhibition purposes, thus dividing the donated collections of survivors and assigning items from the donation to one of the four series, which themselves became collections.
The Lewkowicz family collection, for example, contained both photos and documents. The photos were added, numbered and catalogued according to the metadata schema of the P-series, while the documents were added to the A-series. The only link between the item descriptions was the name of the donor as indicated in the metadata field Côte d’obtention.
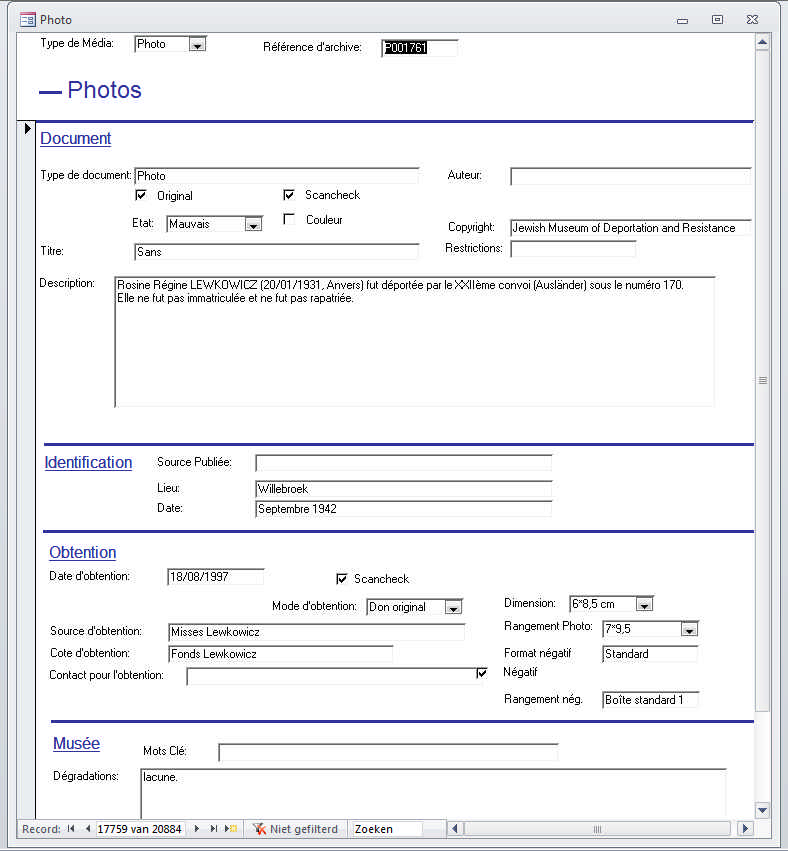
This work method resulted in very detailed and rich descriptions which, because of their original purpose, very often also contained biographical information on the depicted persons or persons mentioned in the document. However, because initially intended to serve the creation of the museum exhibit, the descriptions were work-documents meant for and only accessible to documentation centre staff members. As there were no collection-level descriptions either, the context of the collection and many items as well as the link with the donor was unclear. The system of item descriptions proved hard to use for both non-employees and employees not acquainted with the work methods. The knowledge transfer among staff members and between “generations” of employees was challenging.

The JMDR described its archival holdings on its website in eleven to seventeen collections (the number depends on the version of the institute’s website). The identifiers of the collections changed whenever the website was updated. The collections shown included government series such as the municipal Jewish Register of Belgium and immigration files of Jewish deportees, as well as the four large series created by the JMDR. However, the non-standardized, full text collection descriptions did not contain content details for the A, P, J and T-series. There was for example no information on and no reference to the Lewkowicz family collection in the A- and P-series, so users were not aware of the existence of this collection. Due to a lack of alternatives, when launching its website in 2012 Kazerne Dossin took over the collection presentation method on its webpage. The work method would, however, change after the development of a portal website suited to share collection descriptions.
Adapting the workflow
As of 2011, with the switch from JMDR to Kazerne Dossin, the museum made it its explicit mission to collect, research and share metadata and digital copies of archival collections related to the history of the Holocaust in Belgium. In 2012, the Kazerne Dossin board of directors decided to invest in a digital asset management system. The Media Haven software package was selected to create a closed source portal website via which Kazerne Dossin could share its archival collections, both images of the scanned archives and metadata, with partner institutes worldwide.
At the same time, the European Holocaust Research Infrastructure expressed its wish to bring Kazerne Dossin and its archival collections on board of its archival portal as a test case to analyse methods to standardize archival processes and to identify much-needed tools to help collection holding institutes to share their descriptions with researchers and other institutes. This partnership would lead to growing professionalization in preservation, digitization and description standards for Kazerne Dossin.
During EHRI’s first phase (2010-2015), Kazerne Dossin focused on reworking the archival methods and materials it inherited from the JMDR. EHRI coached Kazerne Dossin when introducing good practices and standardized archival methods, and stepped in to adapt the existing infrastructure (as the institute’s databases were created and maintained in MS Access). The most challenging and at the same time most important step in this phase was, however, to master the jargon, or in other words: to learn to speak ICT and implement ICA standards in order to communicate with the IT staff members of EHRI and the software provider, and transmit this to the documentation centre’s staff.
The partnership with EHRI allowed Kazerne Dossin to quickly grow towards a more standardized and thus more broadly usable format. A first important step was to accord unique and persistent identifiers to all archival collections received as of 2012. Also, all new collections would be described on collection-level according to the ISAD(G) standard and no longer on item-level (except for photos). This had the double advantage of (1) allowing to process and provide information on archival collections much faster (since writing descriptions on a collection level are considerably less time-intensive than on item level) and (2) allowing more broadly sharable descriptions as collection-level faces fewer challenges on privacy regulation than item level descriptions.
Subsequently, based on the name of the donor, items donated before 2012 and catalogued in the A, P, T and J series were recombined into their original collection and described on collection level. The documents and photos of the Lewkowicz family collection were thus reunited in one collection level description. The context of the collection was researched and added to the description. The cataloguing of pre-2012 donations is an ongoing process. Today, dozens of collection descriptions are available via the public end of Kazerne Dossin’s portal website, including the Lewkowicz family collection.

Harvesting and sharing descriptions
Until 2015, due to many changes in Kazerne Dossin’s work flow, EHRI exported the Kazerne Dossin collection level descriptions in CSV from the old MS Access database, which served as a “draft catalogue”. This database was intended as a tool to assemble collection descriptions, before uploading the metadata together with digital images to the portal website. This situation was not ideal, but it allowed Kazerne Dossin to share 253 collection descriptions on the EHRI portal.
That same year Kazerne Dossin tested the APE data preparation tool designed by Archives Portal Europe to import xml files with a valid Encoded Archival Description (EAD) exported from a portal website, into APE to share the collection level descriptions with a broader audience. Although Kazerne Dossin assumed it would be able to export valid EAD directly from its portal website, this tool indicated that the Kazerne Dossin xml files were not compliant with the APE portal site as they did not contain valid EAD. Therefore, Kazerne Dossin could serve again as a test case to install and explore the new tools EHRI was developing.
The EAD Conversion Tool (ECT) was created by EHRI to allow collection holding institutes to map and convert bulk xml files into individual xml files each containing metadata of one collection; the Metadata Publishing Tool (MPT) was developed for collection holding institutes in need of a way to present the xml files for harvesting and publishing on the EHRI portal. Kazerne Dossin served again as a test case since it was not able to export valid EAD, nor was an OAI-PMH available. Kazerne Dossin therefore needed both tools developed by EHRI to be able to provide partners with publicly available xml files containing valid EAD for sharing purposes.
The implementation of tools
EHRI implemented both tools at Kazerne Dossin in June 2017. For the moment, valid EAD is created by converting Kazerne Dossin’s portal website’s raw XML export using the ECT on a client computer. The converted output is then used for the MPT to create a browsable set of files that the harvesters can locate. EHRI assisted in providing documentation, live demo’s and tweaking the tools until Kazerne Dossin was able to get an error-free output (EAD conversion and publishing).
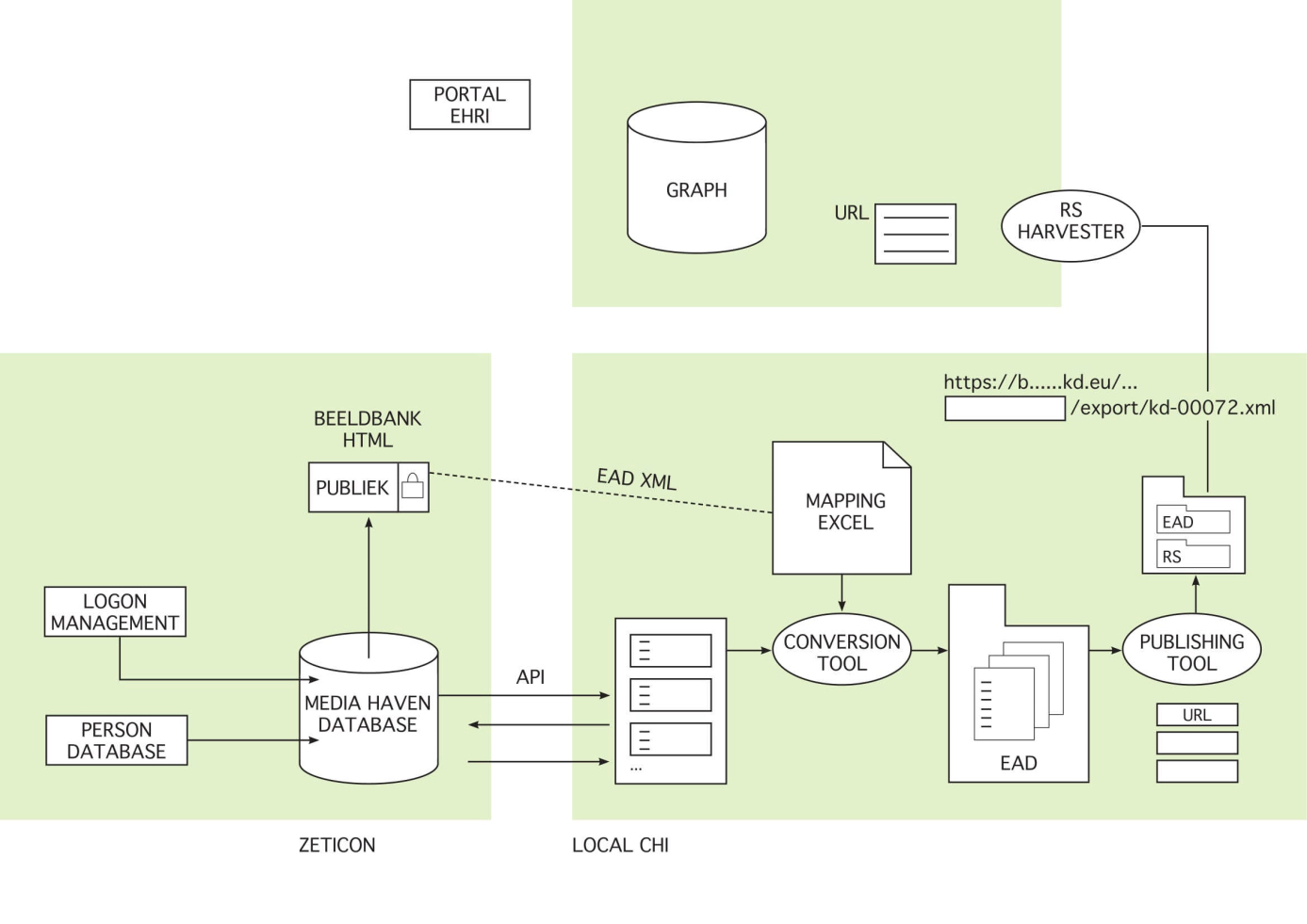
How does it work in practice? Via an Application Programming Interface (API), Kazerne Dossin can export all collection level descriptions from its portal website as a bulk xml. Kazerne Dossin and EHRI together mapped the metadata in this bulk xml on the international standards. During this stage, Kazerne Dossin and EHRI used a trial and error method. The exports were run by EHRI until an error occurred after which the error was solved. The errors in the xml’s on collection level included missing <p>tags; the usage of capital letters in some metadata fields; ISO codes for language, script and country (which were introduced); readability and misunderstandings when mapping the metadata.
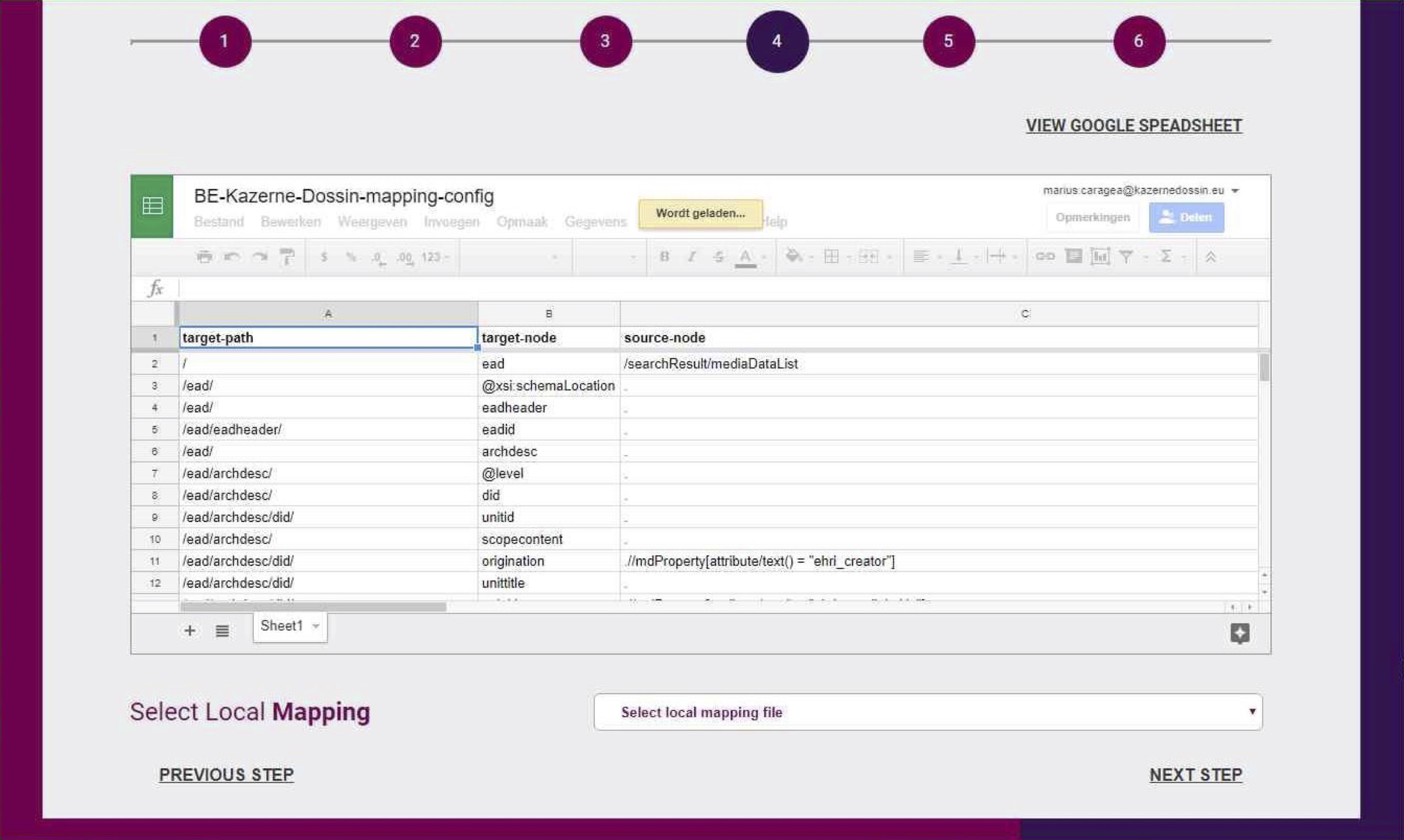
The ECT could thus successfully convert the bulk xml in single xml files, one per collection, compliant with EAD. As Kazerne Dossin had restructured its collection level metadata schema in a prior project phase to fit ISAD(G), no principal, conceptual differences in data structure were identified during the mapping phase.
The Metadata Publishing Tool was then used to create URL’s for every xml file. Two folders – one containing the xml files with valid EAD and another regarding resource synchronization – were offered to interested partners via an accessible endpoint on the Kazerne Dossin server. The folder processed by the Publishing tool is deployed to a simple website that the harvesters can access. For security reasons on the server, the folder browsing functionality is disabled and a direct link to the folder with the exported EAD files could not be provided. One of the collections currently awaiting export is the Lewkowicz family collection.
With the current manual process, periodical exports can be planned. However, in order to automate the process, an extra (tool) implementation is most likely required between Kazerne Dossin’s portal website’s API: providing automatically/scheduled raw XML exports at regular bases and the ECT will transform the exports to valid EAD.
Today, Kazerne Dossin has advanced enormously in its archival work thanks to EHRI. Although the resource sync tool is not yet fully operational and the ultimate goal is to have both the ECT and MPT in an automated process (with auto-generated files automatically published on the website), Kazerne Dossin now has the opportunity to share valid EAD with partner institutions. Kazerne Dossin and its archival holdings’ visibility has improved and it gives the documentation centre the opportunity to join other initiatives and connect its (meta)data with partner projects and institutions worldwide. Hundreds of Kazerne Dossin’s collections will be shared online, honouring thousands of deportees such as Rosine Régine Lewkowicz, her parents, brother and sister who were all killed in the Holocaust, leaving only one brother to survive.