Archivists, historians and relatives of people who’ve been involved in the Holocaust all struggle with the same problem when exploring the vast sea of data related to that epoch – they are not able to obtain all documents related to a given person.

There could be several reasons for that – the documents are spread over different databases across the globe, some of them may be available only upon authorized request, or simply available only on paper or scanned images which are difficult to search. Moreover even if all records are digitized and accessible online, a search machine may not be able to understand that they indeed relate to the same person – something which could be obvious for a human. We’d like to share more about the latter case below.
We’ve been exploring the USHMM survivors and victims database, it contains over 3 200 000 person records (as of June 2015) gathered over time from heterogeneous sources. To be more specific, here is a person record of Zoltan Grun. It contains some data about him such as location and date of birth, information about his mother, location and date of death, as well as which is the source of all that information. In this case, it is a document “HL0115001” in the USHMM archive. Some of the persons in the database are represented by more than one such record. The records come from different sources – lists of arrests, lists of convoys, etc. Different records may contain various information – some may be more complete than others. Even if a bunch of records contain information about the same person, they are not linked to each other.
Here is an example:

- https://www.ushmm.org/online/hsv/person_view.php?PersonId=3428503
- https://www.ushmm.org/online/hsv/person_view.php?PersonId=5843067
Both records are related to a person called Zoltan Grun: the dates of birth are the same; the places of birth too; the name of mother in both records is the same; the place of death of Zoltan (1) is the same as the place where Zoltan (2) got disabled. For a human, these similarities may be enough to consider that these two records are describing the same person and need to be linked. However, for a machine algorithm this is not always so easy and we’ll see why.
Since the exploration of person data is one of the most common tasks in the Holocaust research, we consider it important to find an automatized way to link these records and allow for better search and discovery of data related to the survivors and victims of the Holocaust. We call this task record linking or also record deduplication which is achieved through record matching. The final goal of this task is to have a single record representing each person that contains the references to all the separate records related to him available from the different sources.
We solve this problem by a combination of statistical and rule-based models which could be roughly split into the following tasks (as also shown in Fig. 1):
- Record normalization and enrichment – we transform the properties to their normalized values and where possible we link them to existing knowledge base concepts.
- Classification – we classify each person record against a number of similar candidates to find out whether they are indeed duplicates or not.
- Clustering – we use the result of the classification step as a distance measure between the records and cluster them in groups. Each group of records represent a single person.
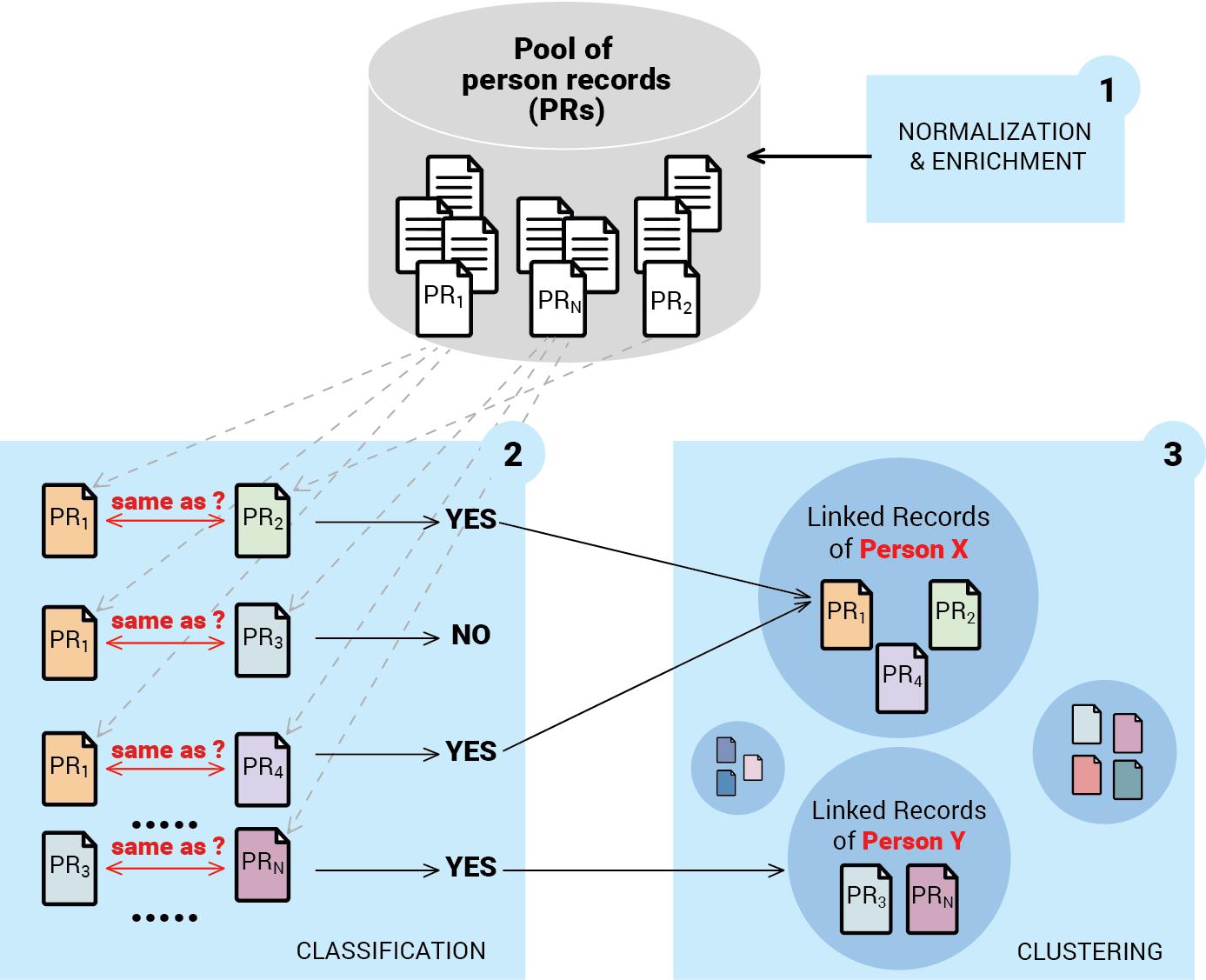
The Person Records
Each person record has up to 375 fields/properties (name, date of birth, date of death, mother’s name, etc.). Most of them are plain text literals and can contain various transliterations, languages, list of values, etc. which hamper the matching between records. Here are some examples:
(1) place_of_birth: “Mukacevo (Czechoslovakia), Czechoslovakia” in one record and “Mukačevo” in another record.
(2) name: “Schmil Zelinsky” in one record and “Schmul Zelinsky” in another record; both records are related to the same person.
Similarly to the human, our machine algorithm classifies whether the two records are related to the same person or not based on the comparison of the separate properties of the two records. Now, you can imagine how difficult it is for a machine to judge whether the two Schmil Zelinsky/Schmul Zelinsky records are actually related to the same person. To find out if they are, we add some heuristics, which help us make the matching of the two records possible.
In addition to the variation of the literals, the properties are sparsely distributed, which could be seen in the figures below.
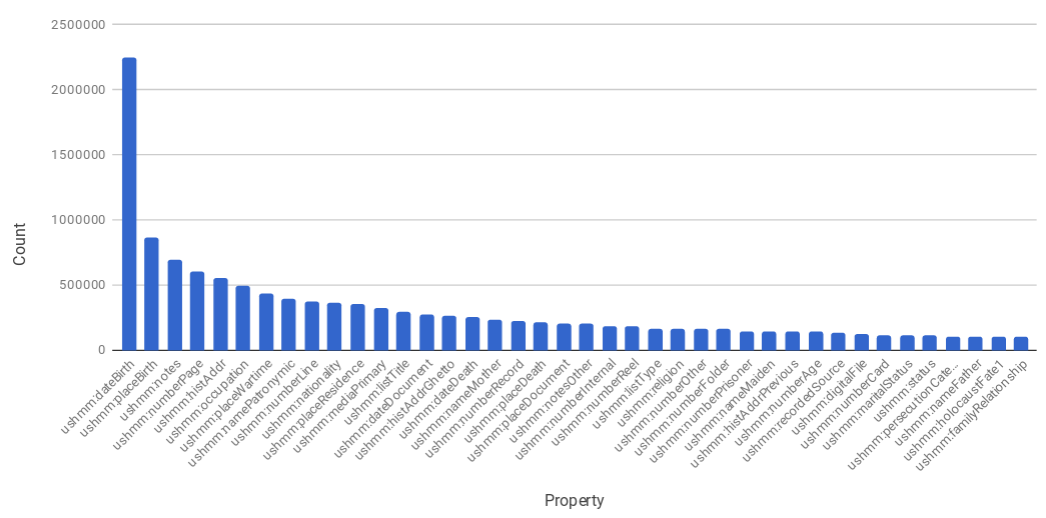
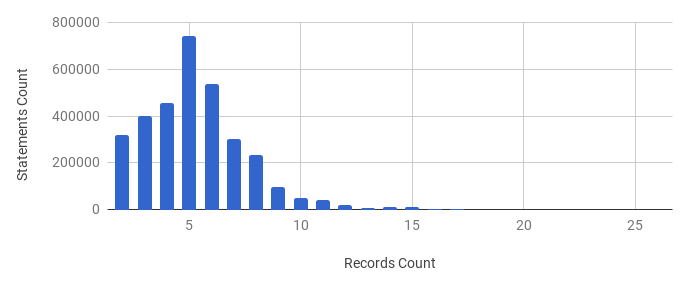
From these figures we see that only 40 properties (out of 375) appear more than 10 000 times in the database of over 3 mln records (Fig. 2). The most popular properties are dateBirth, placeBirth. The majority of the records (96%) have between 2 and 9 properties only, which fall into the bell of the distribution in Fig. 3. The number of records having larger amount of properties is so small that they can be hardly visualized on this chart. It turns out that our algorithm could rely on a very limited number of properties which could be used for making a decision whether the two records are duplicates or not. We chose these properties based on occurrence, i.e. we selected the ones that occurred most often together – name, date of birth, date of death, place of birth, place of death, gender, occupation and nationality.
Making the Match Possible

I mentioned earlier that we apply some heuristics, which help us find out that some names, dates and/or locations are very close matches. The first step in this process is normalization where we try to unify the literals of the properties as much as possible without changing their meaning. These are procedures affecting the orthography, the encoding and removing of some unnecessary symbols. Here are some of the normalization procedures we apply on the names:
- convert all non-Latin characters, accented and special characters occuring in names to ASCII in order to improve the probability of matching;
- convert the names to lowercase;
- remove all digits (0 – 9) and dashes;
- transliterate all symbols to Latin;
- convert the name into Unicode NFKD normal form;
- remove all combining characters, e.g. apostrophes (“’”, “’”, “`”), spacing modifier letters, combining diacritical marks, combining diacritical marks supplement, combining diacritical marks for symbols, combining half marks;
- replace punctuation characters (one of !”#$%&'()*+,-./:;<=>?@[\]^_`{|}~) with spaces;
- replace sequences of spaces with a single space;
- remove any character different from space or lower case Latin letter;
- remove all preceding or trailing white spaces;
- convert the name to title case.
Another property of the person records, which we adjusted, is the gender. It is an important characteristic when judging whether two records correspond to the same person. However, it is often missing. We applied two different procedures for predicting the person’s gender and filled in the missing values in the database.
We trained a statistical model for automatic predicting of the person’s gender based on name suffixes with various length (1, 2 and 3), first name of the person, concatenation of the first and last name and nationality. In addition to this approach, we also inferred that:
- If there were persons with different gender but with the same name, we did not assign a gender for the records having that same name and unknown gender.
- Otherwise, if there was another person with the same whole name and known gender, we assigned the same gender to the person with unknown gender;
- Otherwise, if there was another person with the same first name and known gender, we assigned the same gender to the person with unknown gender.
Finally, as part of the matching task, we also worked out the locations which are available in the person records – place of birth, place of death or place of arrest and other locations. They are also available as literals only and may be written in various ways as in the example with Mokachevo above, so we normalize them by resolving them to GeoNames locations with the help of a service developed by Ontotext, which is specifically adjusted to the EHRI specific domain. The GeoNames URIs are also added to the database and used to train our statistical algorithm. By georeferencing, the literals which point to the same geographic location, no matter of their lexical representation, are also referenced by one and the same GeoNames URI.
E.g. After the georeferencing, both “Mukacevo (Czechoslovakia), Czechoslovakia” and “Mukačevo” are referenced by the same GeoNames URI: http://geotree.geonames.org/700646/
This way when we facilitate the computation of the similarity between locations and avoid the lexical differences in the way they are written in the person records.
Ground Truth
Machines learn by examples, similarly to the way kids do. When we provide enough positive and negative examples for given fenomena, the machine algorithm learns to recognise whether a new given example is positive or negative. For the linking task, our positive examples were couples of person records for which an expert looked up the data and considered them indeed duplicates (positive examples). In the same way, experts collected also pairs of person records which were obviously related to different persons (negative examples). There were also some examples for which the experts could not find enough information to take a decision and considered them as uncertain. We collected 1509 such pairs in total comprising the three cases – positive, negative and uncertain.
We followed 3 different approaches to gathering these examples:
- We chose the top 1000 records by count of their properties and by an iterative procedure for suggesting candidates (including pairs having the same name; same last name; similar date of birth and similar place of birth; same first name and same last name; and similar birth date; etc.).
- Another part was selected relying especially on the attributes which show more value like first name, last name, date of birth and place of birth. We selected records having these properties and grouped them by place and date of birth and selected the top 500 pairs from the groups.
- Then we added also some 9 examples which we collected ad-hoc and represented interesting cases.
The Actual Matching
As we talk about similarity between two records, just presenting a pair of records to the algorithm wouldn’t be useful without specifying how similar these records are. For this reason, we converted each pair of records to a similarity vector between various properties of the records such as the similarity between the name of person A and person B; the similarity between the date of birth of person A and person B, etc. The elements of this vector looked like this:
- Lexical similarities of names – we calculate how similar are the first person names, the last person names and the mother names. We used three different measures to calculate the similarities:
- Jaro-Winkler Similarity
- Levenshtein Similarity
- Beider Morse Phonetic Codes Matching – taking in account the way the names sound, not only the way the names are written.
- Birth dates similarity
- Birth place similarity – for finding similarity in locations we use several features:
- Lexical similarity
- Linked geonames URIs match – yes/no
- Hierarchical structure of Geonames in order to predict the country where data is missing
- Genders Match (Male, Female) – yes/no
- Person Types Match (victim, survivor, rescuer, liberator, witness, relative, veteran) – yes/no
- Occupations Match – yes/no
- Nationalities Match – yes/no
Once the person record pairs are transformed into such vectors (classification instances), where each vector element has the meaning of how similar the corresponding properties of the two records are, we considered that the algorithm had enough information to learn correctly. So, we supplied our ground truth data to the algorithm and let it learn. The algorithm we used is multithreaded sigmoid perceptron classifier.
Clusters of Matched Person Records
We measured the performance of our algorithm in means of F1 measure (a harmonic mean of the precision and coverage of the classified instances). The best obtained model for classifying pairs of person records achieved the following overall mean scores:
- 93% F1 for the class POSITIVE;
- 88% F1 for the class NEGATIVE;
- 43% F1 for the class UNCERTAIN.
The mean macro F1 score is 75%.
Once we have classified the incoming pairs as positive, negative or uncertain, we want to cluster them in a way that each cluster represents a unique person among the set of all clusters. In one cluster there may be one or many person’s records, all related to the same person. Each clustering algorithm requires a measure of distance between two instances in order to decide whether they are close enough to be in the same cluster. As a distance measure, we use the probability assigned by the classifying algorithm for the given pair of instances to be labeled as POSITIVE. The clustering algorithm is DBSCAN. The algorithm was first validated on the training data and then run on the full database and here is what we obtained (Fig. 4).

Here are some examples of the clusters:
Example (1) A cluster of 3 records: The family name of the first person is different from the other two but it sounds suspiciously close and his birth date is also very close to the others.

- https://www.ushmm.org/online/hsv/person_view.php?PersonId=6434661
- https://www.ushmm.org/online/hsv/person_view.php?PersonId=6429128
- https://www.ushmm.org/online/hsv/person_view.php?PersonId=6418737
Example (2) A cluster of 5 records: All records seem to refer to the same person August Fuhrmann.

- https://www.ushmm.org/online/hsv/person_view.php?PersonId=2996015
- https://www.ushmm.org/online/hsv/person_view.php?PersonId=4430175
- https://www.ushmm.org/online/hsv/person_view.php?PersonId=4433342
- https://www.ushmm.org/online/hsv/person_view.php?PersonId=4433343
- https://www.ushmm.org/online/hsv/person_view.php?PersonId=4433344
Example (3) A cluster of 5 records: Here we see a separate cluster which seems to contain records referring again to the same August Fuhrmann and needs to be merged with the cluster in Example (2).

- https://www.ushmm.org/online/hsv/person_view.php?PersonId=4433345
- https://www.ushmm.org/online/hsv/person_view.php?PersonId=4442252
- https://www.ushmm.org/online/hsv/person_view.php?PersonId=4442559
- https://www.ushmm.org/online/hsv/person_view.php?PersonId=4443021
- https://www.ushmm.org/online/hsv/person_view.php?PersonId=4443328
Thorough evaluation of the clusters and error analysis are still to be conducted and if necessary adjustments to the clustering procedures can be done.
Conclusion
This was an initial study on the USHMM Survivors and Victims Database which aim was to prove the applicability of our approach to record linking. It showed that the task is feasible and could be performed with quite a high accuracy. With the cooperation of a human and such an algorithm, the records of over 250 000 people who were involved in the Holocaust could be interlinked in comprehensible amount of time and effort. On the way this will propagate to improved retrieval of documents regarding concrete personalities and will facilitate archivists and researchers in their work and will help the relatives of these people to find out more exhaustive information about them.
By solving this task we get one step closer to overcoming the main challenge of Holocaust research – the wide dispersal of the archival source material across the globe. Furthermore, by supporting the work of an extensive network of researchers, archivists and private individuals, EHRI is able to initiate new transnational and collaborative approaches to the study of the Holocaust.
Michael Levy
Thank you for this interesting article!
At the time the name records from the USHMM Holocaust Survivors and Victims Database was shared with EHRI partners for the purpose of this kind of research in 2015, there were approximately 3.2 million name records published on the web. There was a much larger number of records available internally, but that could not be published on the public web due to various restrictions. As Ivelina Nikolova indicated, these records were collated from many thousands of sources, each source coming with its own characteristics, history, metadata fields, and restrictions. Currently there are 5.7 million person records published on the web (of about 7.5 million total in the HSV database).