In this blog post we introduce a prototype tool for OCRing and querying digitised historical documents, quod, which can be used for organising large collections of such documents.The work described represents a proof of concept, where the feasibility of the idea is demonstrated.
Background
The archives of the International Tracing Service (ITS) in Bad Arolsen, Germany, which focus on the topics of wartime incarceration, forced labour, and liberated survivors, have among their holdings a collection of approximately 4.2 million images (photographs) of documents that have been rearranged without taking into account their provenance. This makes it difficult — or at least highly laborious — to determine, for example, to which subcollection an image originally belongs, or, conversely, to find documents from certain subcollections; or to organise the collections in certain ways — for instance, to separate all documents issued by institute A from those issued by institutes B, C, etc.
ITS has rearranged many of its collections following the needs of the tracing tasks. As a consequence it is relatively easy to search for names of persons in the collection. Yet, at the same time, due to the loss of provenance and context information it is hard to approach the collections with other questions. In the example looked at for this project, for example, it would be very relevant and helpful, both for internal reasons as for researchers outside the ITS, to be able to define employers of forced labourers and even arrange the collections according to these.
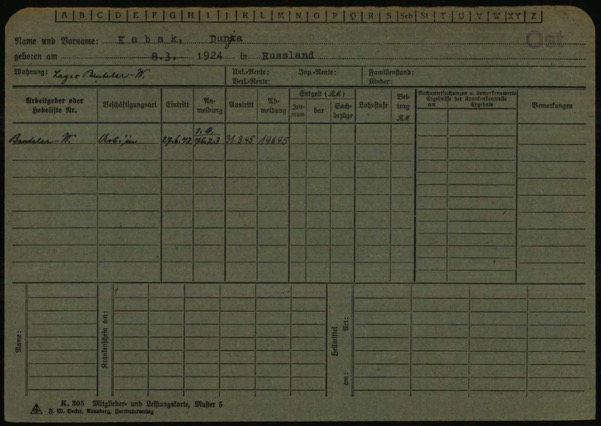
The usability of this collection can be improved significantly (i) by unlocking it, i.e., by making it machine-readable and thereby open to querying, and (ii) by organising it automatically. As this blog post will show, the former can be seen as a prerequisite for the latter, which is the harder task. Improving usability in such manners is an endeavour that is well-suited to WP13 of the EHRI project. In order to explore the development of a tool that can map individual images in the collection to the subcollections these images (or, to be strict, the documents they depict) stem from, or, alternatively, that can group images of the same type together, the ITS provided us with a sample data batch. This batch consists of 899 folders, organised alphabetically by surname, containing a total of 3192 images of 1519 documents, the grand majority of which comprises two pages (only 11 documents are more extensive, and there is only a single one-page document). Among the documents we find various forms, Arbeitsbücher, personal correspondence, etc. This sample data batch is accompanied by Teilbestand 2.2.2.1: Kriegszeitkartei, a card index containing 2858 entries (Inventareinträge) — the subcollections the images (i.e., all 4.2 million of them) stem from, and to which they must be mapped back again. Figure 1 shows an example of such an index entry.

From an information retrieval point of view, organising this collection by means of mapping images to subcollections can be interpreted as a classification task, whereas organising it by means of grouping images of similar document types together can be interpreted as a clustering task. This blog post focuses on the former, showing how we developed a prototype tool that uses optical character recognition (OCR) techniques to convert images into plain text files, which subsequently can be queried and classified using keywords.
Workflow and tools
We set up a five-step workflow, where each step builds upon the previous:
- test set creation;
- determination of the optimal configuration of preprocessing steps;
- OCRing of the preprocessed images;
- querying of the OCR output;
- classification of the images.
It must be noted that the workflow is recursive in that step 2, the determination of the optimal configuration of preprocessing steps, necessitates step 3 and step 4 to be performed repeatedly until this optimal configuration is determined. For this reason, in what follows, steps 3 and 4 will be explained prior to step 2.
In steps 2-4, we made use of open source tools as much as possible. For the preprocessing we used ImageMagick (version 7.0.6-3), a library of tools for editing images that reads and writes images in a variety of formats, and for the OCRing we used Tesseract (version 4.00.00 alpha — note that this version is under active development; the latest stable version is 3.05.01), an OCR engine that can recognise more than 100 languages out of the box, that has unicode (UTF-8) support, and that enables various output formats. Both can be accessed from the command line.

Test set creation
In order to be able to evaluate which configuration of preprocessing steps yields the best OCR results, the data must be annotated. This, however, has to be done manually, which, with a sample data batch of some 3200 images, is rather time-consuming and inefficient. We thus decided to annotate only a subset of the data we have. We did this by traversing the first 100 folders (containing 432 images of 212 documents — approximately 14% of the total sample data batch), checking each image for its document type (its name, e.g., Personenregisterkarte or Zivilarbeiter(in)), and selecting all images that depict the first page of a document type that appears at least twice in these 100 folders. This resulted in a test set of 66 images of 14 different document types. Within this set, we further distinguished between images in which the document type appears in large print at the top of the document (50 images, nine document types) and images in which it appears in small print at the bottom (16 images, five document types), for which we expected adequate OCR to be more challenging. Figure 2 and 3 give an example of both.
OCRing
Optical character recognition, a research field in computer vision and artificial intelligence, denotes the conversion of images of text, be it printed, typed, handwritten, or any combination thereof, into character encodings commonly used in electronic data processing, such as ASCII. By digitising printed texts, their content is opened up for electronic searching, editing, and analysing, and can be used in computational processes such as machine translation or text mining. Nowadays, OCR systems are generally capable of recognising text with a very high degree of accuracy — but their performance depends strongly on the quality of the image files, and also on the quality of the images (i.e., of what is depicted) themselves. The images at hand unfortunately neither have a high file quality (the file size is generally below 350 KB) nor a very high image quality — they are, for example, often noisy (e.g., contain speckles or have the other side shines through) or distorted (e.g., skewed or rotated 90 or 180 degrees). Additional complications are that they contain mixed font types (any combination of printed, typewritten, and handwritten texts is encountered) and mixed alphabets (Roman an Cyrilic). OCRing these images is thus a challenging task.
When OCRing an image, the Tesseract OCR engine must be provided at least two arguments: the name of the input file and the name of the output file. Given only this minimal information, however, the engine will revert to its default settings — the most important implications of which are that the language used will be assumed to be English, and that the OCR engine mode, which determines which underlying trained model is used, will be based on what is available In addition to the compulsory arguments, we therefore provided as optional arguments the language used (which we set to German) and the OCR engine mode (which we set to 1 for long short-term memory, or LSTM, neural networks).
Querying
After OCRing all images, we queried each output file for each string in the list of document types that we compiled. If a match was found and the query string was the correct document type for the image corresponding to the output file, a true positive (TP) was counted; if a match was found but the query string was not the correct document type, a false positive (FP) was counted; and if no match was found but the query string was the correct document type, a false negative (FN) was counted.
The query string may consist of a single word or of multiple words — more formally, it contains n substrings. The output file, which is represented as a list of tokens (words), will thus be traversed token for token, where the substring consisting of the current token and the n-1 following tokens is compared with the query string.
We used an approximate string matching technique, where the match ratio threshold determines whether a match is found. The match ratio, first, is a number that determines to which extent two strings are equal; it ranges between 0 (indicating full inequality) and 1 (indicating full equality), and is calculated using the SequenceMatcher class from the Python difflib module. The match ratio threshold (MRT), then, determines the minimum match ratio required for two strings to be considered equal. The MRT thus offers flexibility in strictness when evaluating the similarity of two strings. However, a too high MRT value can result in an abundance of false negatives being retrieved, whereas a too low value can result in an abundance of false positives. The MRT therefore is another parameter to optimise; we experimented with five different values: 0.8, 0.75, 0.7, 0.65, and 0.6.
Preprocessing optimisation
In the Tesseract documentation it is stated that “in many cases, in order to get better OCR results, you’ll need to improve the quality of the image you are giving Tesseract” — in other words, that some preprocessing is required. The aim of preprocessing is to improve the image by suppressing undesired distortions (e.g., skew) and removing irrelevant information (e.g., background noise), and highlighting relevant information (e.g., by improving contrast), so that the image is clean and features that are important for further processing stand out. A quick look into the literature, or, simply, the list of ImageMagick tools available, reveals that there are many possible ways in which an image can be edited. In the Tesseract documentation, five commonly tried operations are explicitly suggested:
- rescaling, where the size of the image is changed;
- binarisation (or thresholding), where each pixel is reassigned to one of only two possible values (generally, its minimum or maximum value), which increases contrast and separates foreground and background;
- denoising, where noise such as speckles or a background image is removed;
- deskewing, where a rotation is performed so that lines of text are not tilted;
- border removal, where any borders, which can be falsely recognised as text, are removed.
Using these suggestions as a guide, we experimented with different combinations of the first four of these operations — the fifth, border removal, seems less relevant in the case of the data we are working with. Furthermore, since the functionality of the corresponding ImageMagick tools is parameterised, we additionally experimented with different parameter values, as shown in Table 1.
| Tool | Parameter | Parameter controls | Values tried |
| -scale | geometry | the scaling ratio | 113%, 125%,
138%, 150% |
| -threshold | value | the threshold value above which pixel values are set to the maximum pixel value | 13%, 25%, 38%, 50% |
| -noise | radius | the width of the noise reducing pixel window | 1, 2, 3, 4 |
| -deskew | threshold | the minimal skew an image must have in order for it to be deskewed | 40% (recommended) |
Table 1: The image ImageMagick tools used for preprocessing, their parameterisation, and the values tried.
Rather than for an exhaustive approach, in which all possible configurations are tried, we opted for a greedy approach, in which, iteratively, all available preprocessing operations are tried in combination with the optimal preprocessing configuration so far (starting with no preprocessing), and the one that yields the highest result is added to the optimal configuration so far. This is repeated until adding a preprocessing operation no longer improves the results.
Preprocessing optimisation results
The effectiveness of each preprocessing configuration tried was evaluated by OCRing the preprocessed images (step 3 in the workflow, as explained above), and then querying the resulting output files for the document types (step 4 in the workflow, as explained above). We used precision, the fraction of retrieved documents relevant to the query (or TP/(TP+FP)), and recall, the fraction of the relevant documents retrieved (or TP/(TP+FN)), as the evaluation metrics. We found that, for all MRTs, the optimal preprocessing configuration is deskewing and scaling to 113%; the precision and recall values obtained using this configuration are shown in Table 2.
| MRT | prc | rcl |
| 0.8 | 1.0 | 0.65 |
| 0.75 | 1.0 | 0.67 |
| 0.7 | 0.87 | 0.73 |
| 0.65 | 0.75 | 0.73 |
| 0.6 | 0.46 | 0.83 |
Table 2: Precision (prc) and recall (rcl) values for the optimal preprocessing configuration (deskewing and scaling to 113%) per MRT.
Table 2 also clearly shows that when the MRT is decreased, precision values also decrease, while recall values increase — see also Figure 3. As mentioned above, this behaviour is to be expected: higher MRTs will result in more false negatives being retrieved, thus lowering recall values, while lower MRTs will result in more false positives being retrieved, thus lowering precision values. However, this can be used to one’s advantage: if the aim is simply to retrieve as many relevant documents as possible, even at the cost of getting a significant amount of irrelevant documents as a by-product, a low MRT may be used. If, however, the aim is to retrieve only relevant documents, then a high MRT should be used.

Application: image querying and classification using keywords
The OCR-and-query approach as described above was implemented in a prototype Python-based command line tool called quod (querying OCRed documents). quod can be used either to OCR images and subsequently query them, or only to query previously OCRed images. The tool takes four compulsory arguments and is invoked using the following command:
$ quod path query mrt ocr
where
- path is the path containing the files to OCR and query; these files may either be directly inside the path, or inside separate subdirectories within the path;
- query is the query string and may consist of multiple substrings, in which case it must be placed in quotation marks;
- mrt is the match ratio threshold, as explained above;
- ocr is a Boolean value that defines whether the images must be both OCRed and queried, in which case it is set to true, or only queried, in which case it is set to false (the values yes or y and no or n are accepted alternatives).
All arguments are case insensitive. Thus, to give an example, the following command will, after first having OCRed all images in the directory ~/imgs, have the resulting output files (which will be stored along the images) queried for the term Mitglieder- und Leistungskarte, using an MRT of 0.7:
$ quod ~/imgs ‘mitglieder- und leistungskarte’ 0.7 true
For each match found, the name of the image corresponding to the output file in which the match is found is added to the list that is returned.
One straightforward way to start organising an unstructured or disordered collection such as the ITS’s Teilbestand 2.2.2.1 automatically — which in this particular case means to map the individual images in the collection to the subcollections they stem from — is to represent each subcollection by means of a salient keyword, and then use quod to retrieve all images containing that keyword. Twelve of the subcollections, for example, contain documents related to the industrial conglomerate Reichswerke Hermann Göring. Querying the complete sample data batch that the ITS has provided us using the keyword ‘hermann goring’ (omitting the umlaut) and an MRT of 0.75, 20 documents are retrieved. A manual check shows that all of these are relevant, giving a precision of 1.0 (recall cannot be calculated as the complete data is not annotated). Similarly, four of the subcollections contain documents related to AEG, a producer of electrical equipment still extant today. Using the keyword ‘aeg’ and, because of the brevity of the query, a higher MRT of 0.85, 22 documents are retrieved. However, in this more demanding case, only nine of the documents retrieved are relevant, giving a precision of 0.41.
By extracting keywords from Teilbestand 2.2.2.1 and adding them to a list which is then given to quod, the above process can be scaled up. Keyword extraction can be manual (and thus laborious), but techniques such as named entity recognition are likely to be very useful in automating it.
Conclusion
In this blog post we introduced the prototype tool quod for OCRing and querying digitised historical documents. As the work described represents a proof of concept, both the approach and the tool itself can be improved and refined. For example, the test set, which needs to be annotated manually, is very small, which hampers proper preprocessing optimisation; currently, only one query string can be used, and the matching process is rather simple; and the use of the tool for classifying documents, which at the moment has to be done fully manually, is still in its infancy. Furthermore, a number of methodological questions remain, relating, among other things, to test set annotation (how can we create a larger annotated test set?), performance statistics (how can these be improved or refined?), scaling (can the approach be applied to the full data set of 4.2 million images?), generalisation (how can other archives make use of the tool?), or metadata (how can we make better use of existing metadata, such as file names and directory structures?).
Using the tested tools gives an outlook on possible improvements for using the ITS archives. The tools, even if still to be improved, could make it possible to rearrange parts of the ITS collections following provenance and/or sources of the documents received by manifold institutions. This would be a major improvement for accessing the ITS records and would facilitate research on a wider range of topics. At the same time the outcome of this test has shown that digitisation processes (that have begun many years ago at the ITS) need to be modified to simplify future OCR-related projects.