With over 22,000 hours of audio and video testimony in the United States Holocaust Memorial Museum’s collection and available online, we face a search and discoverability problem. Visitors to the collection can only find certain interviews by sheer luck or by looking for a certain person’s name. Creating catalog information for the hours of testimony presents a problem – we do not have enough staff to listen to everything. It presents a barrier to entry for researchers, genealogists, and the general public. A researcher looking for stories of children from mixed jewish-Christian families who survived the war in Germany would miss Ginger Lane’s interview entirely. Only recently interviewed by the Museum, Ginger’s story is not searchable by anything other than her name. She offers a unique look at the experiences of Jewish children living in Germany during the war, and until her interview is cataloged it is not findable.
Our oral history collection is deep and it is wide. Comprised of interviews produced by the Museum and collected from outside organizations conducted in over a dozen languages, creating catalog records and transcripts presents a logistical challenge. We are exploring crowdsourcing transcripts using a platform called Amara to increase access to this rich resource.
EHRI‘s Work Package 13 tasks includes an exploration of crowdsourcing projects as a means of enhancing access to Holocaust materials. Crowdsourcing projects may require a great deal of engineering infrastructure, marketing, and community organizational work. Here is a brief report on an ongoing crowdsourcing project accomplished with few resources and could be accomplished by any institution with any media streamable in a web browser.
Harnessing the Power of the Crowd to Improve Access
Crowdsourcing oral history transcripts presents many challenges. What tool should we use? Can we scale a project up? Who would do quality control? What about accents that are difficult for transcribers to understand? Specific geographic place names the general public is unfamiliar with? And, importantly, would people be interested in doing this work? Crowdsourcing not only offers opportunities for the Museum to enhance its collections, but it also offers a way for the public to engage with our collections, to interact with primary sources, and to learn more about Holocaust history.
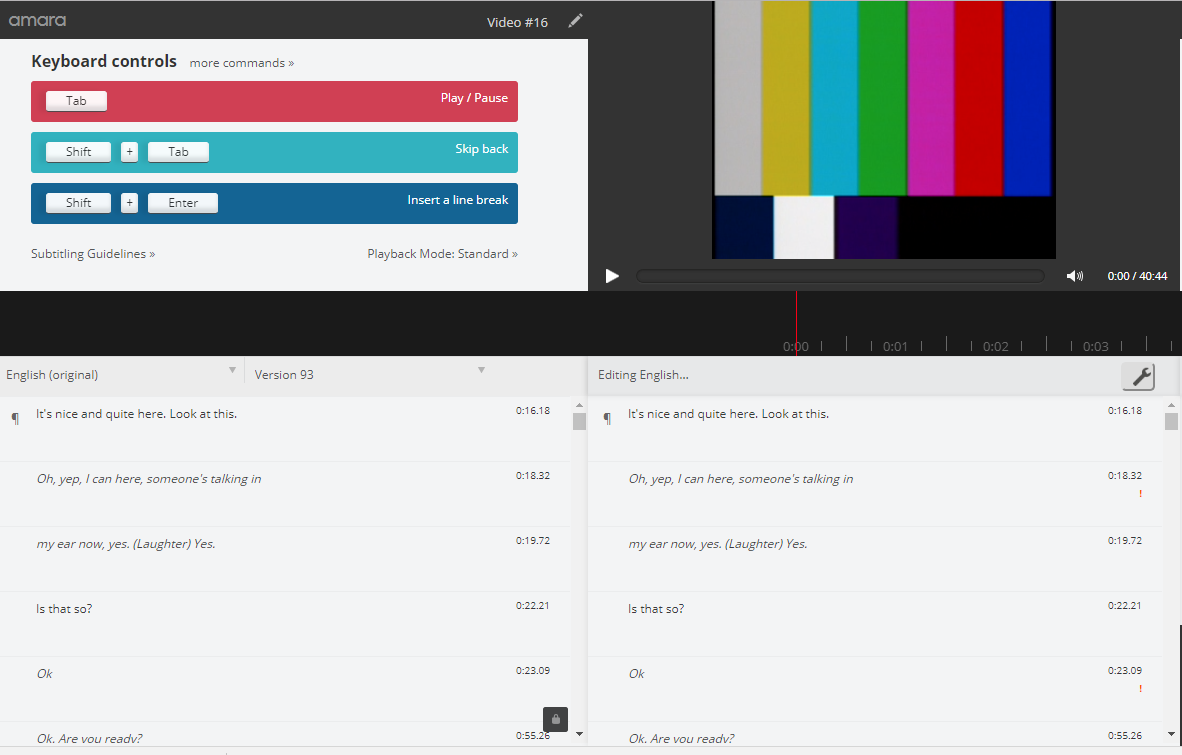
We researched different tools and approaches to creating transcripts and finally settled on using Amara for a small scale crowd sourced project. Amara is a project by the non-profit Participatory Culture Foundation dedicated to building a more open collaborative world and making online video content accessible to everyone. They have built a tool to transcribe online video content and then add time codes for closed captioning. Part of Amara’s claim is that its Transcribing Tool is fun and easy to use.
While conducting this research, high school sophomore Jack R. approached the Museum about volunteering in 2014. He and I sat down to talk about the need we had to create not just transcripts of our interviews, but also the need to improve accessibility to our oral history collection for people who are deaf and hard of hearing. Creating time coded transcripts that can be used for closed captioning or rolling transcripts are a step in that direction. Jack’s interest in history and hard work helped us learn how to use the Amara transcribing tool successfully.
Working with High Schoolers
In 2015, after working on his own with Amara Jack’s experiences listening to and transcribing the stories of Carmen Villalba (in French, no less!) and Joseph Engel convinced him to introduce Amara to his high school’s history honor society. This would not only help the Museum improve access, it would also help his classmates learn more about the history of the Holocaust and give them the chance to work closely with primary sources before going to college. Together with his teacher, we created a program for members of the club to transcribe interviews. Jack’s enthusiasm, hard work and leadership helped build a successful small scale crowdsourced transcription pilot project. We discussed together how to deal with the difficult subject matter in the Museum’s interviews and accents that proved difficult for students to decipher. We decided for the purposes of this project to focus on interviews with liberators, nurses, and lawyers who spoke English with an American or British accent.
Process
The students at James Madison work from a joint account created by staff at the Museum. The interviews they work with are all between 30 and 60 minutes long and in English. Student volunteers work on a set of interviews communally until the transcript is finished. Amara provides an easy to use transcription

platform. A volunteer can rewind in six second segments or slow the speed of the video to make it easier to type what the person is saying.
We were able to discover many problems that would arise – how to deal with false starts and interruptions, what to do when an interviewee misspeaks – in the year we worked with Jack. He became a “super volunteer” overseeing the other students at his school, providing real time support, correcting spelling, and identifying areas where Museum staff needed to provide guidance.
Once a transcript is complete, volunteers “sync” the transcript to the video creating subtitles to play along with the video. The Museum has chosen to use WebVTT chapter files to display the subtitles in our Collections Search. WebVTT files provide time code for the speech that should be displayed on the screen. You can see an example of what a WebVTT chapter file looks like below.
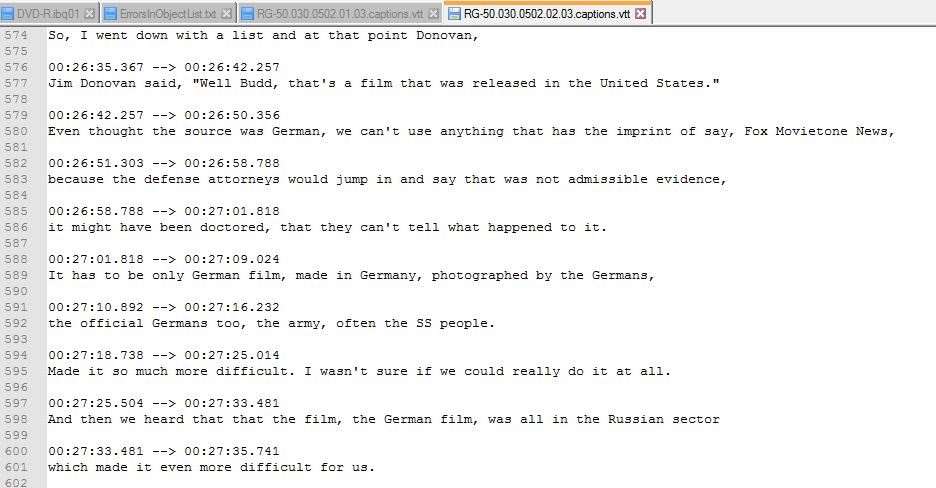
We use a database to track the creation of these WebVTT files and display them through the JWPlayer in our Collections Search. The files are delivered using a popular commercial cloud object storage platform along with the streaming MP4 file. All interviews – cataloging information, streaming MP4 files, finding aids, and these time coded subtitles – are tracked and brought together on a file name. Agnes Mandl Adachi, who as a young woman survived the war in Budapest and Romania under the protection of Raoul Wallenberg and the Swedish embassy, offers a look at how we are able to display all of the elements of an interview in one interface. You can find her interview here in our online catalog.
Lessons Learned Along the Way

Students have had a positive experience working in Amara’s platform. Although the work can be difficult and requires attention to detail, students find it rewarding to get to interact closely with primary source material. They also have the opportunity to explore aspects of Holocaust history not touched on in school. In order to scale a project like this to a larger “crowd”, we will need to establish clear workflows to ensure we receive quality transcripts. Someone who could effectively manage a volunteer corps and track progress would be essential to such a project.
Possibilities for the Future
Given the success of working with students, we have recently expanded to include a retired teacher among our group of volunteers. After initial training, she has also found Amara an easy-to-use tool to create verbatim time coded transcripts. We only have a small number of completed Amara transcripts at this time and are experimenting with how best to make them accessible. If you visit our website today, you won’t see any subtitles – yet. However, with few resources and free tools we have begun to explore whether crowd sourced transcriptions of Holocaust oral testimonies is a viable project at the United States Holocaust Memorial Museum and other similar institutions. With Amara we have found a tool that makes interacting with streamable media easy enough for students and retirees, but more importantly we have found a new way to engage our audience with one of our collections. While scaling such a project presents logistical challenges, the feedback we have received from our volunteers about how meaningful they find the work might make such a project something worth pursuing.
Try It Yourself
If you go to Amara.org and create a free account for yourself, you can test out Amara for yourself. You simply create an account, log in, click on “Get Started” under the Free Subtitling platform and test out the transcription tool using one of the following stable URLs.
https://oralhistory-assets.ushmm.org/RG-50.030.0003.01.02.mp4
https://oralhistory-assets.ushmm.org/RG-50.030.0003.02.02.mp4
https://oralhistory-assets.ushmm.org/RG-50.030.0902.01.01.mp4