Many Galleries, Libraries, Archives, and Museums (GLAM) face difficulties sharing their collections meta-data in standardised and sustainable ways due to the absence of in-house Information Technology (IT) support or capabilities 1. This situation means that staff rely on more familiar general purpose office programs like text processors, spreadsheets, or low-code databases. However, while these tools offer an easy approach for data registration and digitisation they don’t allow for more advanced uses.
For example, text processors’ content is readable by humans who can interpret and understand the structure and the meaning of what is written. However, machines cannot understand the meaning of the text as it is written in what is called Natural Language (NL) without any predictable structure. NL presents a lot of challenges for the Computer Science field as humans’ way of expressing themselves can include sarcasm, irony, double-meaning, among others. Furthermore, the Ethnologue portal estimates that 7139 languages are spoken today on earth2. A fact that complicates even more the task of the very active research field of Natural Language Processing (NLP) 3. Therefore, encoding meta-data in Word files and PDFs is not a convenient form of preservation as its conversion will be very complex and will rarely – if ever – be able to achieve 100% accuracy for its conversions.
Spreadsheets offer a structured way of registering data which makes them more easily processable by machines than normal text documents. However, they can pose some problems when registering multiple instances (redundancy, empty cells, arbitrary number of columns for the same attribute, etc.) and they do not offer integrity checks, so data can be messy and invalid without users noticing it. These issues are the reason why spreadsheets are not advised as a comprehensive and sustainable method of registering data within an institution. As we have mentioned at the beginning of this post, they are a popular and familiar tool used in many institutions for informal (and sometimes even formal) data registration. This is why we are going to dedicate this post to them in order to see the possibilities to migrate them to more structured and standard formats.
In the case of our latest example, low-code databases offer a similar approach to fully-fledged databases but with less powerful DataBase Management System (DBMS) engines and less functionality. But they do offer a User Interface (UI) that abstracts into a great amount the complexity of administering a complete database. They are a great solution for small offices and teams that want to preserve the information in a sustainable and low-budget way. Compared to spreadsheets they are based on the relational model which allows to normalise data preventing ambiguity and duplicate problems. In addition, they incorporate integrity rules that notify users whenever the inputted data has violated one of the implemented rules, avoiding data ending up in an inconsistent state.
As a side note, these differences and difficulties correlate with the 5-star model proposed by Tim Berners-Lee4 in which the use of open standards, highly structured formats and unambiguous identifiers confer the data with more stars in the proposed classification system. These stars are then understood as how easy your data can be processed and connected with other systems and data, allowing for better data integration and governance.
The case of Czech collections for the Yerusha project
Within the European Holocaust Research Infrastructure (EHRI) project, and more specifically the EHRI Data integration lab, we see many different cases of how an institutions’ IT capability and technological infrastructure lead to different data sharing capabilities and standards adherence. In this post we are going to focus on a case study where we received a set of records from different Czech archival institutions in an Excel spreadsheet5. This format was defined by the Yerusha project6 with the intention of facilitating data sharing for participating institutions. This specific Excel file was created within the Czech Yerusha project by the Jewish Museum in Prague and provided to EHRI in the framework of mutual cooperation and data exchange. In the context of the EHRI project, they shared a filtered version containing only the Holocaust relevant collections. Our final goal was to ingest all these records in the EHRI portal in a way as automated as possible. As a secondary goal we aimed to build a generic workflow that could be applied to more Excel Yerusha imports.
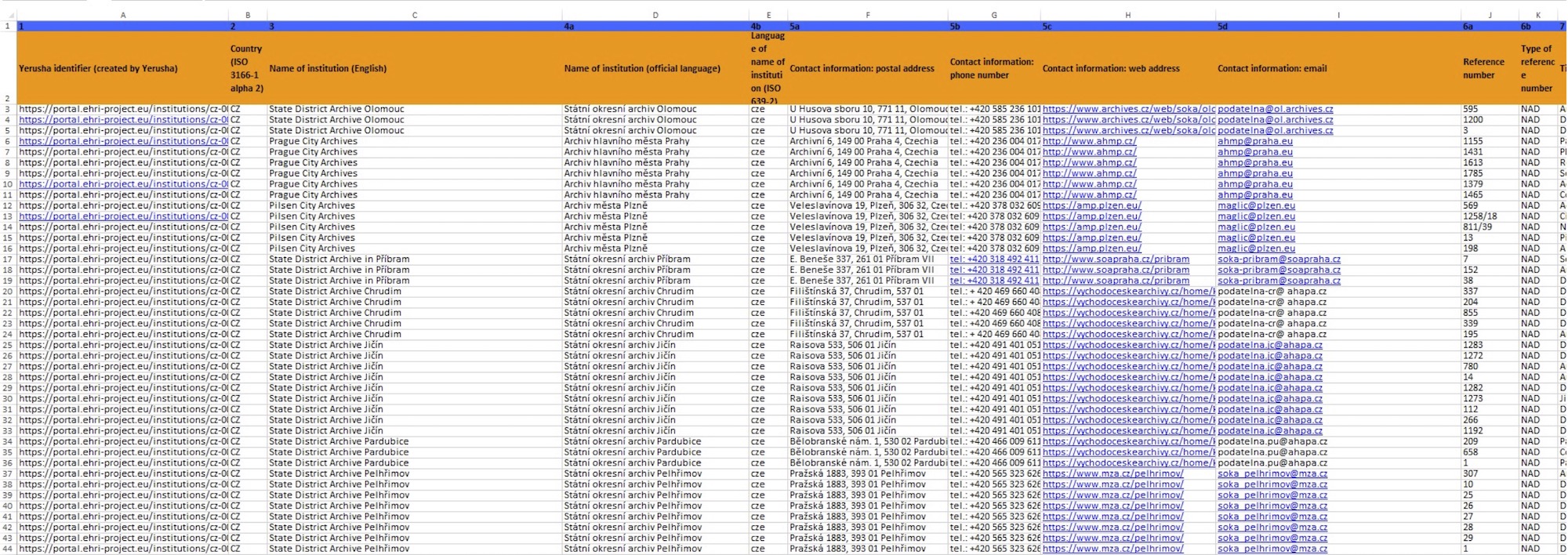
Before going into further detail about the designed workflow, we are going to briefly explain how the data integration tools work in the EHRI portal. The first thing to have in mind is that the EHRI data model used for ingestion is the Encoded Archival Description (EAD)7, meaning that if we are able to provide an EAD-XML compliant file we do not need to perform any additional conversion and the data will be ingested without any problem. However, in many scenarios we have different coverage for EAD (which implies some minor adaptations) and, in other cases, institutions output their data according to different standards (e.g., Dublin Core8) which require a full data model conversion. Therefore, in order to cover all these possible cases, the data integration tools in the EHRI portal are divided in three main categories: harvesting, transformation and ingestion. The harvesting allows users to upload the files to the EHRI portal and also to build the sustainable connections. The transformation phase allows the transformation of harvested files into valid EAD files through some declarative instructions, namely Extensible Stylesheet Language Transformations (XSLT) 9 and EAD Conversion Tool (ECT)10. Finally, the ingestion phase allows to validate the converted data and ingest it into the EHRI portal. More can be read about these tools and how to use them in the documentation web page11. Nevertheless, it is important to have in mind that nowadays Extensible Markup Language (XML) is the only supported format within the EHRI data integration tools, so all the harvested files should be in XML.
Looking at this overview on data integration in the EHRI portal, we established that we would have to perform a conversion outside the EHRI portal, and, in order to avoid a double conversion phase, we should map the Excel file directly to EAD files. It is tempting to think that scripting can solve this problem quite easily and quickly. Although it could solve this problem, these kinds of ad-hoc solutions normally lack the attributes of repeatability (if you need to perform a similar procedure for other data you should develop another script from the scratch), maintainability (a little change in the data could mean a big change in the code) and shareability (only trained users will be capable of using the developed script). Therefore, any solution should cover the mentioned attributes in order to be usable in the future for other cases and also be able to be shared with the whole community, like we are doing in this post.
Tool selection and importing data
The most straightforward solution was to design the workflow using OpenRefine12 which as stated by its creators it is “a powerful tool for working with messy data: cleaning it; transforming it from one format into another; and extending it with web services and external data”. Open Refine is able to: deal with different input formats (including Excel sheets), perform transformations on the data (they will be needed to perform some cleaning and splitting some elements), facet and filtering (required as we have different institutions in the same Excel sheet) and output files in different formats. Moreover, it offers an intuitive UI that allows people to perform transformations on their data with minimal training. In this post we describe the workflow we designed to transform an Excel spreadsheet into EAD files that can be directly ingested by the EHRI portal.
The first step is to install OpenRefine, following the tutorial on OpenRefine’s webpage13. Once you have the tool started you can create a new project by clicking on create project and upload the file directly from your computer. You can get the example Excel file in the dedicated Github repository14 and follow the instructions on your own computer.
It is important that in the preview phase you adjust the following settings: Ignore first line(s) at beginning of file setting it to 1 and Parse next line(s) as column headers setting it to 1. This will ignore the first row with the numbers and will use the second row as the headers for our columns. This is something specifically needed for this spreadsheet as the first row is not useful for our case and it will prevent a correct interpretation of the data by Open Refine. After importing the file, OpenRefine will show us a preview of some rows from the input data. The use of this interface is very similar to the Excel one. If we click on the edit button in any cell we can edit its value. On the column name we can click on the arrow to see the option that we can apply to all the cells in that column, e.g., facet, filter, sort, and transform data.
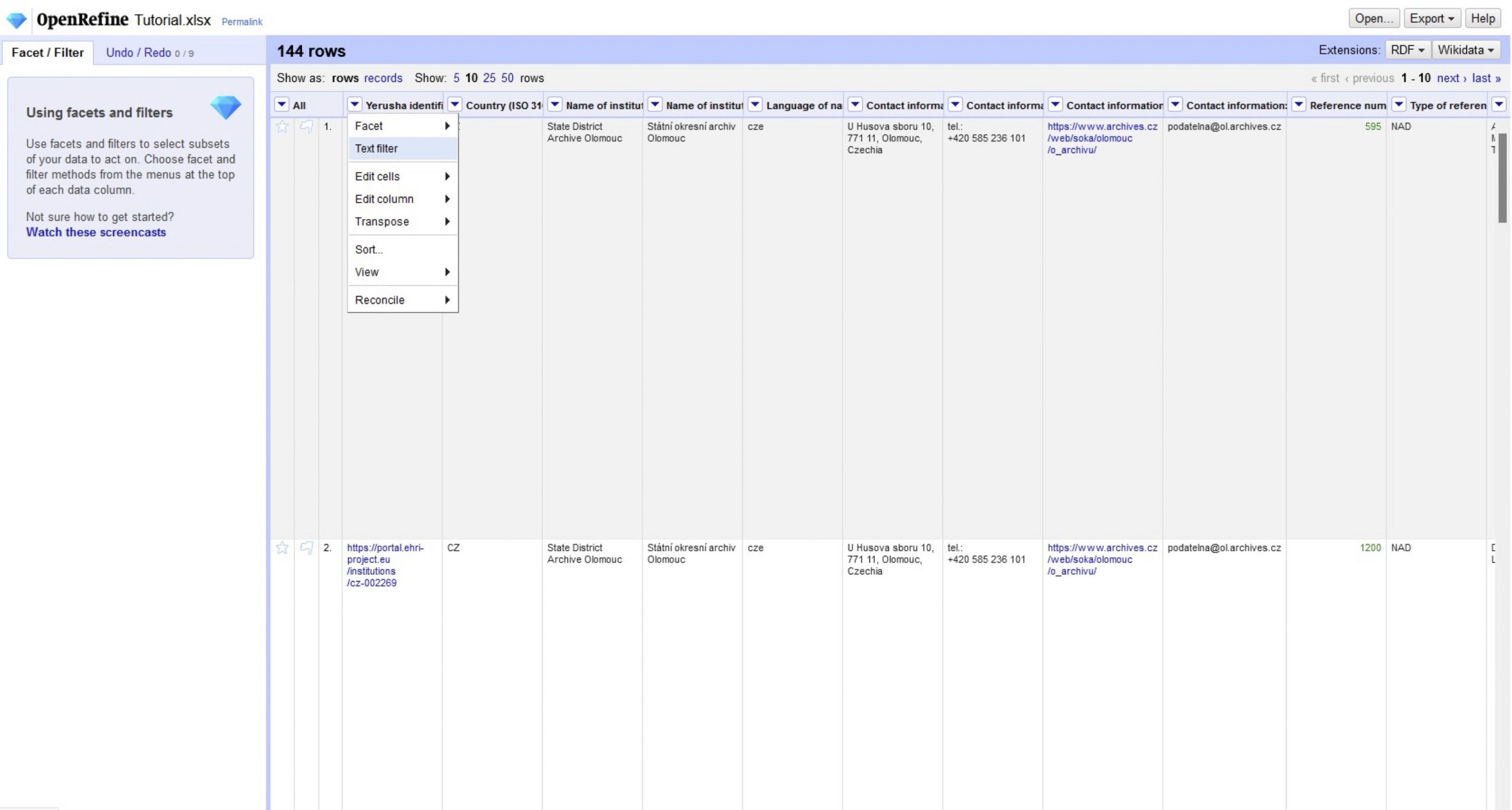
Data transformations
Now we will need to make some transformations in the data as some fields cannot be placed in the XML file in their current state. This is the case for: “Language(s)”, “Access points: locations”, “Access points: persons/families”, “Access points: corporate bodies”, “Access points: subject terms”, “Finding aids”, “Contact information” and “Links to finding aids”. As you can see, apart from “Contact information” all these fields are meant to have more than a single entity. As we have mentioned at the beginning of this post this is one of the problems that spreadsheets pose for data management. In XML files we can hold multiple instances of a value using multiple tags inside another tag. This is known as a sequence which is normally ordered but can also be unordered. In the next paragraphs we are going to see the transformations that we need to carry out in these fields before converting them to EAD.
We are going to start with the column that only needs some data normalisation: “Contact information”. If we take a look at the data we can see that telephone abbreviation can appear in two forms (i.e., “tel.:” or “tel:” ). In this case we want to remove any kind of abbreviation from the data as we want the raw number with the prefix. Then, we choose the “Edit cells”, “Transform…”. Here we can write some code that performs a transformation per value. In our case we are going to use the “Python / Jython” language (select the Open Refine option with the same name). Then introduce the following snippet of code:
import re pattern = re.compile(r"(t|T)el.?:?") return pattern.sub("", value)
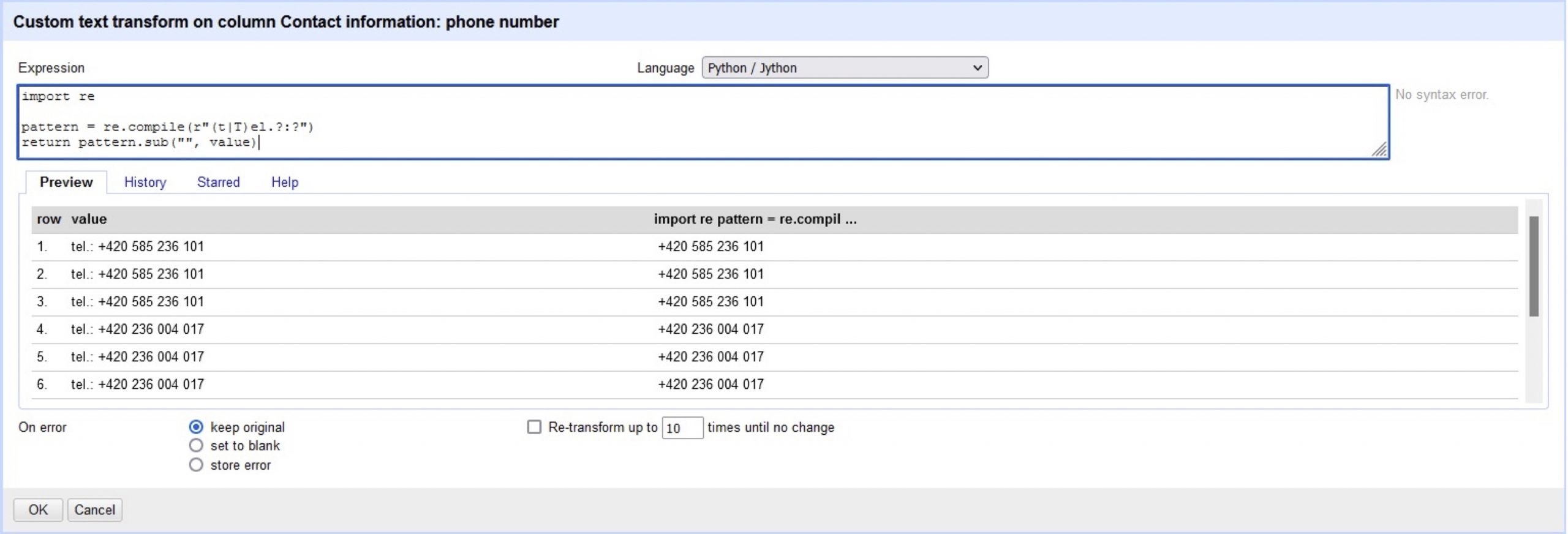
As shown above, this removes the telephone abbreviations as expected. This snippet relies on Regular Expressions which are syntactic constructions that allow for a certain pattern within a text to be searched. This can be then used to match and replace parts of a text in a very effective and concise manner. In our case we are using it to match both ways that telephone has been abbreviated but it can also take into account the omission of the final colon. Then, it just removes the matching sub-sequence, leaving only the raw number as we wanted.
Now we are going to deal with the multiple values in one cell taking “Language(s)” as a simple example. In this case we have multiple languages encoded with their ISO 639-3 code and divided by a semicolon. The latter is crucial as we need this separator to tell the software where one language code ends and another one begins. As we did with the “Contact information” field we are going to apply a transformation to this column, using the following code:
f = lambda i: '<language langcode="%s">%s</language>' % (i.strip(), i.strip()) return "".join(map(f, value.split(';')))
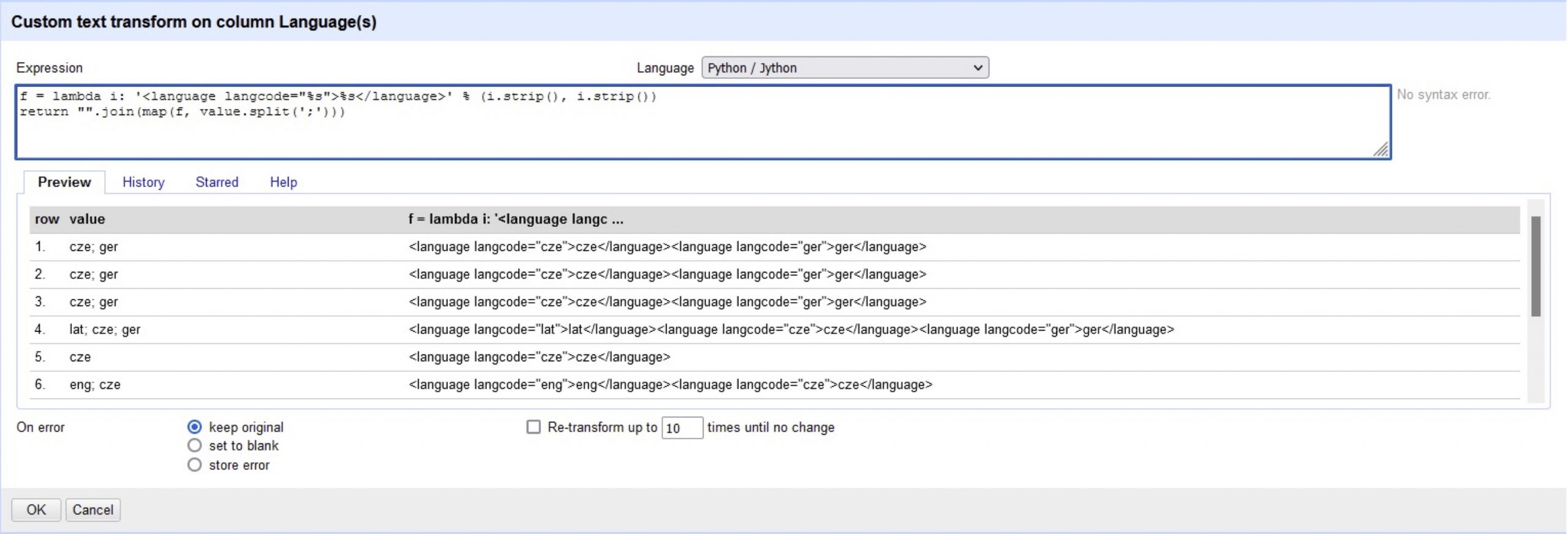
This snippet divides the value using the semicolon as the separator, then leading and trailing spaces are removed and for each value it creates the language tag following the XML syntax as shown in the image. A similar procedure is possible for the rest of the mentioned fields using these snippets:
“Access points: locations”:
f = lambda i: '<geogname>%s</geogname>' % (i.strip()) return "".join(map(f, value.split(';')))
“Access points: persons/families”:
f = lambda i: '<persname>%s</persname>' % (i.strip()) return "".join(map(f, value.split(';')))
“Access points: corporate bodies”:
f = lambda i: '<corpname>%s</corpname>' % (i.strip()) return "".join(map(f, value.split(';')))
“Access points: subject terms”:
f = lambda i: '<subject>%s</subject>' % (i.strip()) return "".join(map(f, value.split(';')))
“Finding aids”:
f = lambda i: '<otherfindaid><p>%s</p></otherfindaid>' % (i.strip()) return "".join(map(f, value.split('; ')))
“Links to finding aids” (in this case instead of the semicolon we are using the line break to split the values):
f = lambda i: '<p>%s</p>' % (i.strip()) return "".join(map(f, value.split('\n')))
Faceting the data for exporting
Before exporting the data, we will have to group the collections according to the institution they come from. To do that we can use the “Yerusha identifier (created by Yerusha)”, “Name of institution (English)” or “Name of institution (official language)” fields and go to the option “Facet”, “Text Facet”. A panel will be shown in the left side of the window with the different values for this column. To only show the collections from a specific institution we can select it from the list and the rows will be filtered accordingly. Now we can start the export process, taking into account that we have to change the institution in each export to create all the EAD files.
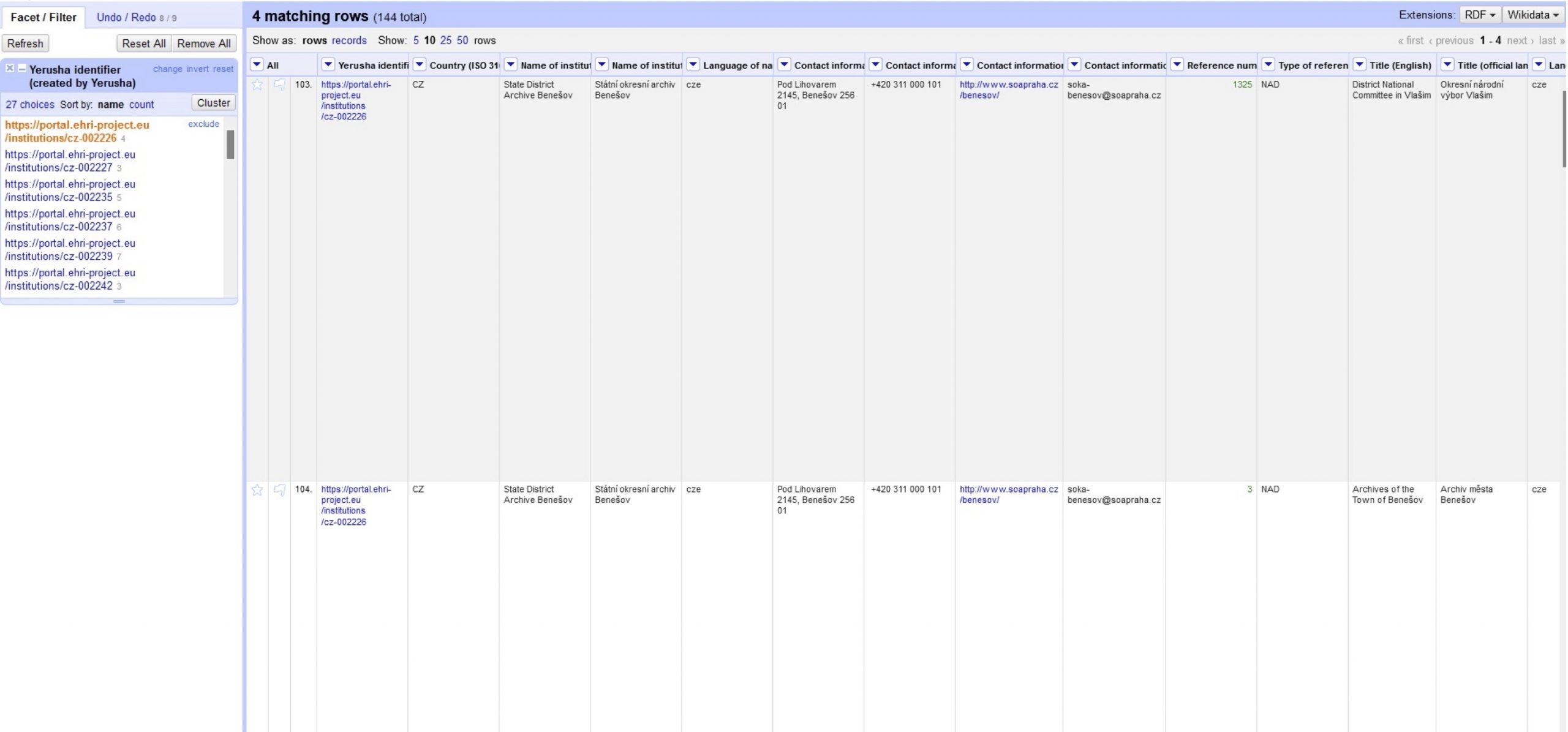
It is possible to export all the data at once (and then perform a slicing) or to export each record separately (no slicing required). However, as the EHRI portal works in an ingestion per institution model, we can only group the files that belong to the same institution. Therefore, following the faceted model, we can click on “Export”, “Templating…”. Here, OpenRefine allows us to format the output that we want using free text and including the values from our transformed table as we want. Therefore, we can put an EAD template and include the expressions to extract the values. Remember that we have already transformed multiple values on multiple XML tags, so we have this issue covered already. See the template below for the EAD template:
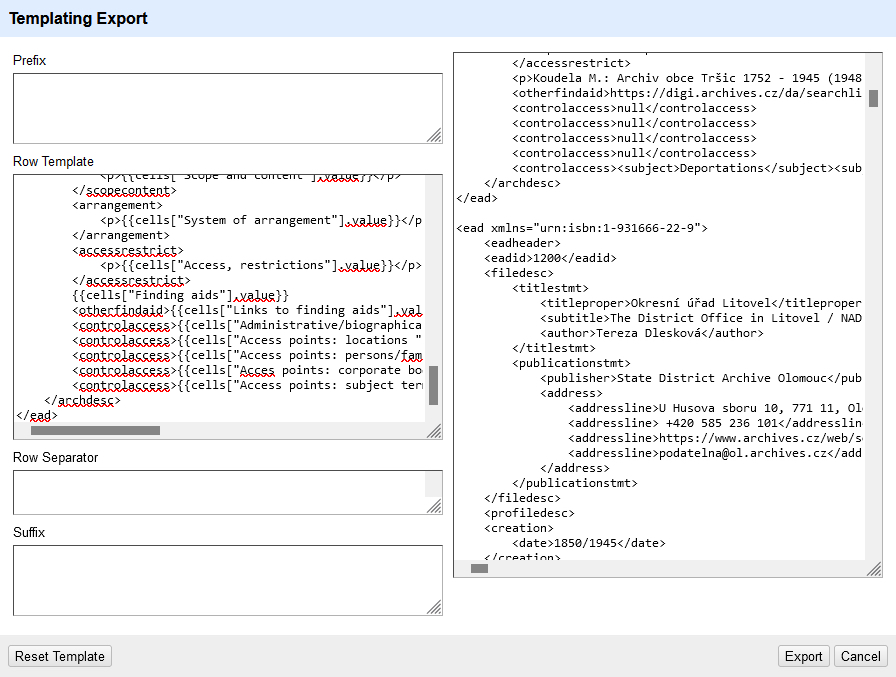
<ead xmlns="urn:isbn:1-931666-22-9"> <eadheader> <eadid>{{cells["Reference number"].value}}</eadid> <filedesc> <titlestmt> <titleproper>{{cells["Title (official language)"].value}}</titleproper> <subtitle>{{cells["Title (English)"].value}} / {{cells["Type of reference number"].value}} {{cells["Reference number"].value}}</subtitle> <author>{{cells["Author of the description"].value}}</author> </titlestmt> <publicationstmt> <publisher>{{cells["Name of institution (English)"].value}}</publisher> <address> <addressline>{{cells["Contact information: postal address"].value}}</addressline> <addressline>{{cells["Contact information: phone number"].value}}</addressline> <addressline>{{cells["Contact information: web address"].value}}</addressline> <addressline>{{cells["Contact information: email"].value}}</addressline> </address> </publicationstmt> </filedesc> <profiledesc> <creation> <date>{{cells["Date(s)"].value}}</date> </creation> <langusage> <language langcode="eng">English</language> </langusage> </profiledesc> </eadheader> <archdesc level="collection"> <did> <unitid>{{cells["Reference number"].value}}</unitid> <unittitle>{{cells["Title (official language)"].value}}</unittitle> <physdesc> <genreform>{{cells["Type of material"].value}}</genreform> <genreform>{{cells["Type of material 2"].value}}</genreform> <physfacet type="condition">{{cells["Physical condition"].value}}</physfacet> <extent>{{cells["Extent"].value}}</extent> </physdesc> <repository> <corpname>{{cells["Name of institution (English)"].value}}</corpname> </repository> <unitdate>{{cells["Date(s)"].value}}</unitdate> <langmaterial> {{cells["Language(s)"].value}} </langmaterial> <origination> <name>{{cells["Creator /accumulator"].value}}</name> </origination> </did> <odd> <p>{{cells["Title (English)"].value}} / {{cells["Type of reference number"].value}} {{cells["Reference number"].value}}</p> </odd> <custodhist> <p>{{cells["Archival history"].value}}</p> </custodhist> <bioghist> <p>{{cells["Administrative/biographical history"].value}}</p> </bioghist> <scopecontent> <p>{{cells["Scope and content"].value}}</p> </scopecontent> <arrangement> <p>{{cells["System of arrangement"].value}}</p> </arrangement> <accessrestrict> <p>{{cells["Access, restrictions"].value}}</p> </accessrestrict> {{cells["Finding aids"].value}} <otherfindaid>{{cells["Links to finding aids"].value}}</otherfindaid> <controlaccess>{{cells["Administrative/biographical history "].value}}</controlaccess> <controlaccess>{{cells["Access points: locations "].value}}</controlaccess> <controlaccess>{{cells["Access points: persons/familes "].value}}</controlaccess> <controlaccess>{{cells["Acces points: corporate bodies"].value}}</controlaccess> <controlaccess>{{cells["Access points: subject terms"].value}}</controlaccess> </archdesc> </ead>
So, now we fill the dialog fields with the following values: prefix empty, row template with the mentioned EAD template, row separator with a line break (press the Enter button) and suffix empty. On the right hand side you will see a preview of what OpenRefine is going to export. You can see an example of how the output should look like below. It is very important to ensure that between two different EAD documents, there is the desired line break. If everything is as expected, press export.
Now you have a single file with many EADs inside, you only need to split them in different files using the line break as the separator. For doing so you can use the convenient command below in your preferred terminal. It will divide the big file into small EAD files called part-xx.xml. Note: for opening the terminal you search for the “Terminal” application in Linux and MacOS or “Command Prompt” in Windows. The command csplit might not be installed by default in your Windows or MacOS system, if so, you can either install it or use an alternative command. Remember to change the export.txt for the actual path and filename produced by OpenRefine.
csplit -z -b -%02d.xml -f part export.txt "/<ead .*>/" "{*}"
Conclusions
As mentioned at the beginning of this post, there are many benefits to using this methodology as we can share the procedure and the resources used. In addition, as OpenRefine offers an easy-to-use interface, this workflow can be also explored by non-expert users. Apart from that, designing this complete workflow and the attached export template allows us to apply the same procedure to further data that comes in a spreadsheet but also in other formats supported by OpenRefine which in the end makes this workflow very adaptable and flexible. For new cases little effort is required for data normalisation and cleansing. The same template can be used to produce EAD files that are ready to be uploaded to the EHRI portal.
This post explains a procedure for producing EAD files from an Excel spreadsheet using OpenRefine. We have seen the benefits that this procedure can bring alongside the possibilities that it opens for non-expert users by means of an easy-to-use UI. All the materials and resources used in this tutorial can be freely and openly accessed in the following Github repository15.
- Ruest N, Lin J, Milligan I, Fritz S. The archives unleashed project: technology, process, and community to improve scholarly access to web archives. In: Proceedings of the ACM/IEEE Joint Conference on Digital Libraries in 2020; 2020. p. 157-66. ↩
- https://www.ethnologue.com/guides/how-many-languages ↩
- Raina, V., & Krishnamurthy, S. (2022). Natural language processing. In Building an Effective Data Science Practice (pp. 63-73). Apress, Berkeley, CA. ↩
- https://5stardata.info/en/ ↩
- https://github.com/EHRI/DataIntegrationLabResources/raw/main/CzechInstitutions/EHRI-fromYerusha.xlsx ↩
- https://yerusha.eu/ ↩
- https://www.loc.gov/ead/index.html ↩
- https://www.dublincore.org/specifications/dublin-core/dcmi-terms/ ↩
- Clark, J. (1999). Xsl transformations (xslt). World Wide Web Consortium (W3C). URL http://www.w3. org/TR/xslt, 103. ↩
- https://github.com/EHRI/manuals/blob/master/ECT/EAD%20Conversion%20Tool%20User%20Guide_vs2_20180205.pdf ↩
- https://documentation.ehri-project.eu/en/latest/administration/institution-data/datasets.html#the-dataset-view ↩
- https://openrefine.org/ ↩
- https://docs.openrefine.org/manual/installing ↩
- https://github.com/EHRI/DataIntegrationLabResources/tree/main/CzechInstitutions ↩
- https://github.com/EHRI/DataIntegrationLabResources/tree/main/CzechInstitutions ↩